

















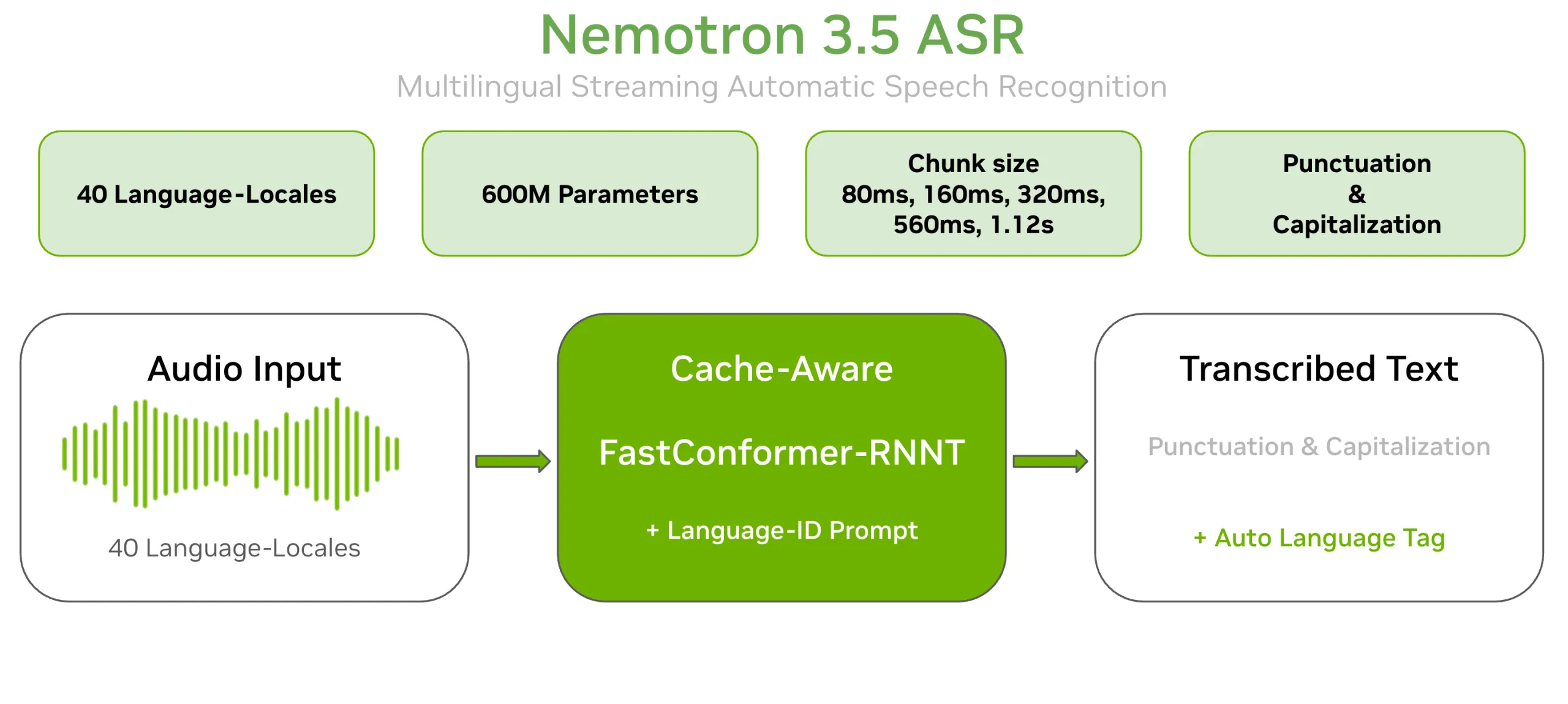
NVIDIA’s Nemotron Speech team has released Nemotron 3.5 ASR. It is a 600M-parameter streaming Automatic Speech Recognition (ASR) model. A single checkpoint transcribes 40 language-locales in real time. Punctuation and capitalization are built in natively. The model ships as open weights on Hugging Face. The license is OpenMDW-1.1. The architecture is a Cache-Aware FastConformer-RNNT.
What is Nemotron 3.5 ASR
Nemotron 3.5 ASR extends nvidia/nemotron-speech-streaming-en-0.6b to many languages. It adds prompt-based language-ID conditioning to the base model. That lets one 600M-parameter checkpoint cover 40 language-locales. No per-language model or model-swapping is required.
The model targets two workloads. The first is low-latency streaming for live audio. The second is high-throughput batch transcription. Output is production-ready text with proper casing and punctuation. No separate punctuation-restoration step is needed.
How Cache-Aware FastConformer-RNNT Works
The model has two main pieces. The first is a Cache-Aware FastConformer encoder with 24 layers. FastConformer is an efficient evolution of the Conformer architecture. It uses linearly scalable attention. The second piece is an RNNT (Recurrent Neural Network Transducer) decoder. RNNT emits text frame by frame as audio streams in.
The “cache-aware” design is the efficiency lever. Buffered streaming re-processes overlapping audio windows at every step. That repeats the same work and adds delay. This model caches encoder self-attention and convolution activations instead. It reuses those cached states as new audio arrives. So each audio frame is processed exactly once, with no overlap. Compute and end-to-end latency both drop, without an accuracy penalty.
The Latency Knob: att_context_size
One inference setting controls the latency-accuracy tradeoff. It is the attention context size, att_context_size. Smaller context emits text sooner but sees less future audio. Larger context raises accuracy at higher latency.
The same checkpoint covers the full range. Settings map to chunk sizes of 80ms, 160ms, 320ms, 560ms, and 1.12s. For example, [56,0] gives an 80ms ultra-low-latency mode. The [56,13] setting gives 1.12s for highest accuracy. Teams pick the operating point at inference time, with no retraining.
Language Detection and Coverage
The 40 language-locales include English, Spanish, German, and French variants. They also cover Arabic, Japanese, Korean, Mandarin, Hindi, and Thai. Several other European and Nordic languages are included too.
Language conditioning works two ways. Setting target_lang to a known locale usually gives the best accuracy. Setting target_lang=auto lets the model detect the language itself. In auto mode, it emits a language tag after terminal punctuation. One deployment can then transcribe mixed-language traffic. No separate language-ID component is required.
Comparison
| Product | Company | Access | Native streaming | Language coverage | Reported latency | Pricing model |
|---|---|---|---|---|---|---|
| Nemotron 3.5 ASR | NVIDIA | Open weights (OpenMDW-1.1), self-host; hosted on DeepInfra | Yes — cache-aware FastConformer-RNNT | 40 language-locales | 80ms–1.12s, configurable at inference | Free to self-host; usage-based via host |
| Whisper large-v3 | OpenAI | Open weights (MIT), self-host; API | No — offline/batch | ~99 languages | Not streaming-native | Self-host free; API ~$0.006/min (batch) |
| Nova-3 | Deepgram | Closed API; on-premise/self-host (enterprise) | Yes — streaming + batch | Multilingual; +10 monolingual languages added Jan 2026 | Low-latency streaming (reported sub-300ms) | ~$0.0077/min (Nova-3 Monolingual, PAYG) |
| Universal-3 Pro Streaming | AssemblyAI | Closed API (EU endpoint available) | Yes | 6 languages: English, Spanish, French, German, Italian, Portuguese | Sub-300ms (official); first partial ~750ms | Usage-based (PAYG) |
| Scribe v2 Realtime | ElevenLabs | Closed API | Yes | 90+ languages (99 per ElevenLabs) | ~150ms (p50) | ~$0.28/hour |
| Ursa / streaming | Speechmatics | API + on-premise + edge | Yes — streaming + batch | 50+ languages with automatic identification | Ultra-low latency (positioned) | Enterprise/usage |
Fine-Tuning Results
Because the weights are open, teams can fine-tune for a language, domain, or accent. NVIDIA published a worked example on Greek and Bulgarian. It fine-tuned the base checkpoint with the same Cache-Aware FastConformer-RNNT recipe. Each clip carried a target_lang tag for language conditioning. Training data came from public corpora, including Granary, Common Voice, and FLEURS.
Results were measured as WER on held-out FLEURS, at the 80ms setting. Greek WER fell from 35 to 24, a 32% relative improvement. Bulgarian fell from 22 to 15, a 31% relative improvement. These are raw WER percentages at the lowest-latency streaming mode. NVIDIA notes that evaluating at deployment latency, on held-out data, gives honest numbers.
Strengths and Considerations
Strengths:
- One 600M-parameter checkpoint covers 40 language-locales, cutting deployment sprawl.
- Cache-aware streaming processes each frame once, reported at 17x buffered concurrency on an H100.
att_context_sizetunes latency from 80ms to 1.12s at inference, with no retraining.- Punctuation, capitalization, and
autolanguage tagging are built in. - Open weights enabled a 31–32% relative WER drop on Greek and Bulgarian after fine-tuning.
Considerations:
- The model handles English, but NVIDIA recommends its dedicated English model for English-only use.
- The 80ms mode trades some accuracy for the lowest latency.
- Japanese and Korean use CER, so cross-language error comparisons need care.
- Throughput figures are measured on H100, so results on other GPUs will differ.
- The production NIM with gRPC streaming is announced, but not yet released.
Key Takeaways
- NVIDIA’s Nemotron 3.5 ASR is an open-weights (OpenMDW-1.1), 600M-parameter streaming model transcribing 40 language-locales from one checkpoint.
- Its Cache-Aware FastConformer-RNNT design processes each audio frame once, reported at 17x the concurrent streams of buffered approaches on an H100.
- Latency is configurable from 80ms to 1.12s at inference via
att_context_size, with no retraining. - A short fine-tune cut FLEURS WER 32% on Greek (35→24) and 31% on Bulgarian (22→15), at the 80ms setting.
- It is self-hostable and streaming-native, unlike closed APIs (Deepgram, AssemblyAI, ElevenLabs) or offline Whisper.
Marktechpost’s Visual Explainer
NEMOTRON 3.5 ASR
1 / 10
Curated for AI engineers by Marktechpost — practitioner-first coverage of AI & ML.
Check out the Model weights. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us

Credit: Source link










{kind=link}