
















































Generative AI, an area of artificial intelligence, focuses on creating systems capable of producing human-like text and solving complex reasoning tasks. These models are essential in various applications, including natural language processing. Their primary function is to predict subsequent words in a sequence, generate coherent text, and even solve logical and mathematical problems. However, despite their impressive capabilities, generative AI models often need help with the accuracy and reliability of their outputs, which is particularly problematic in reasoning tasks where a single error can invalidate an entire solution.
One significant issue within this field is the tendency of generative AI models to produce outputs that, while confident and convincing, may need to be corrected. This challenge is critical in areas where precision is paramount, such as education, finance, and healthcare. The core of the problem lies in the models’ inability to consistently generate correct answers, which undermines their potential in high-stakes applications. Improving the accuracy and reliability of these AI systems is thus a priority for researchers who aim to enhance the trustworthiness of AI-generated solutions.
Existing methods to address these issues involve discriminative reward models (RMs), which classify potential answers as correct or incorrect based on their assigned scores. These models, however, need to fully leverage the generative abilities of large language models (LLMs). Another common approach is the LLM-as-a-Judge method, where pre-trained language models evaluate the correctness of solutions. While this method taps into the generative capabilities of LLMs, it often fails to match the performance of more specialized verifiers, particularly in reasoning tasks requiring nuanced judgment.
Researchers from Google DeepMind, University of Toronto, MILA and UCLA have introduced a novel approach called Generative Reward Modeling (GenRM). This method redefines the verification process by framing it as a next-token prediction task, a fundamental capability of LLMs. Unlike traditional discriminative RMs, GenRM integrates the text-generation strengths of LLMs into the verification process, allowing the model to generate and evaluate potential solutions simultaneously. This approach also supports Chain-of-Thought (CoT) reasoning, where the model generates intermediate reasoning steps before arriving at a final decision. The GenRM method, therefore, not only assesses the correctness of solutions but also enhances the overall reasoning process by enabling more detailed and structured evaluations.
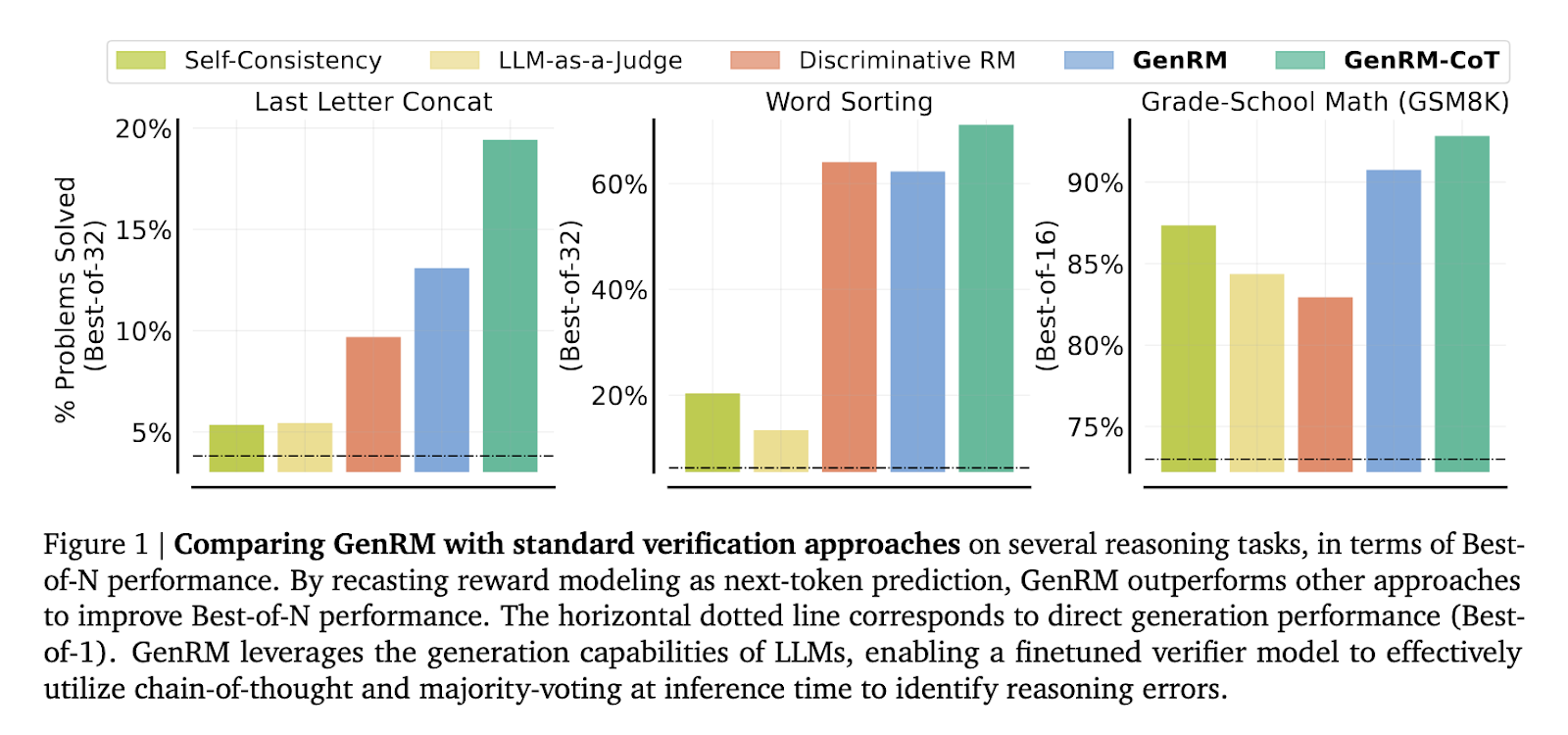
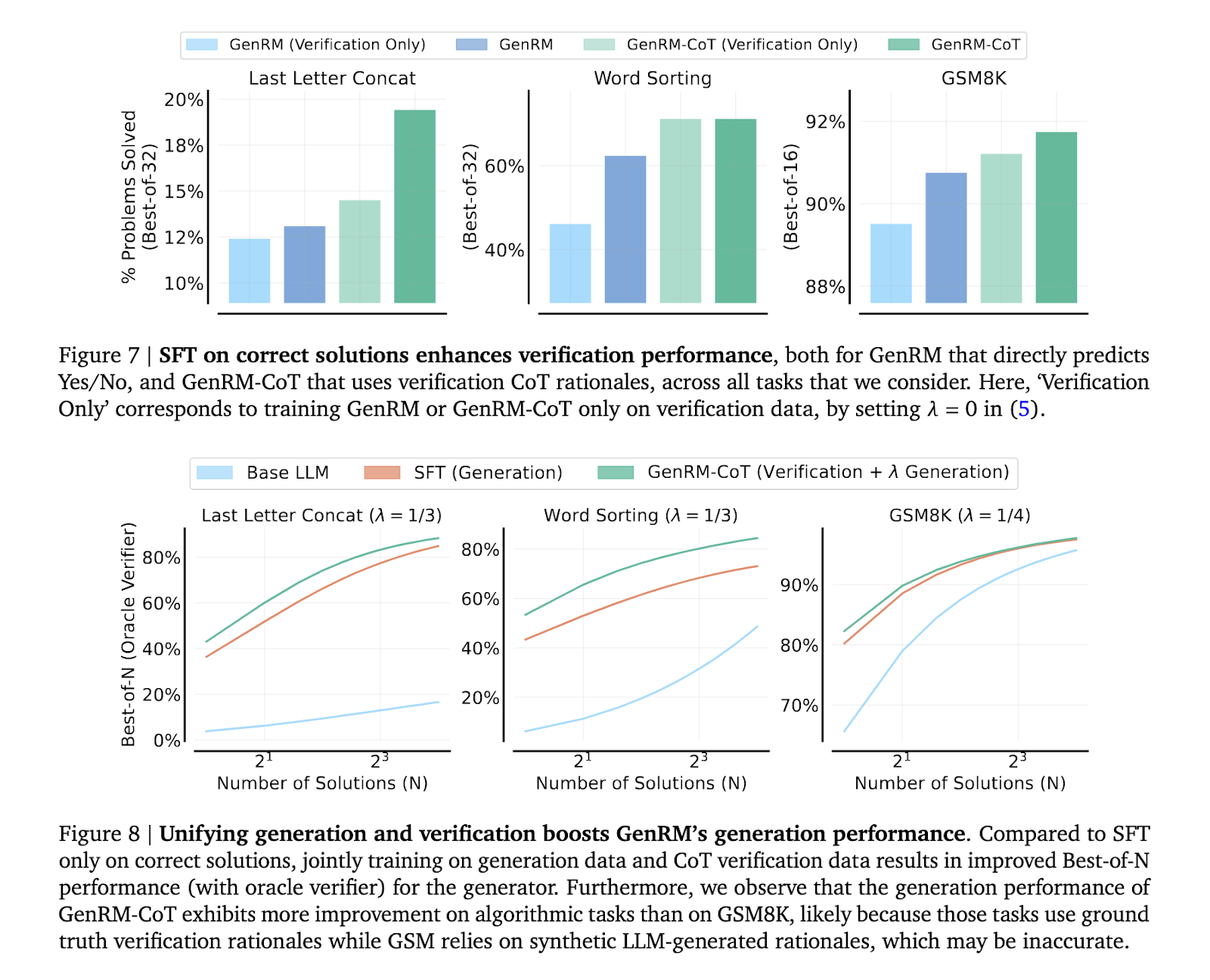
The GenRM methodology employs a unified training approach combining solution generation and verification. This is achieved by training the model to predict the correctness of a solution through next-token prediction, a technique that leverages the inherent generative abilities of LLMs. In practice, the model generates intermediate reasoning steps—CoT rationales—which are then used to verify the final solution. This process integrates seamlessly with existing AI training techniques, allowing for the simultaneous improvement of generation and verification capabilities. Furthermore, the GenRM model benefits from additional inference-time computation, such as majority voting aggregating multiple reasoning paths to arrive at the most accurate solution.
The performance of the GenRM model, particularly when paired with CoT reasoning, significantly surpasses traditional verification methods. In a series of rigorous tests, including tasks related to grade-school math and algorithmic problem-solving, the GenRM model demonstrated a remarkable improvement in accuracy. Specifically, the researchers reported a 16% to 64% increase in the percentage of correctly solved problems compared to discriminative RMs and LLM-as-a-Judge methods. For example, when verifying outputs from the Gemini 1.0 Pro model, the GenRM approach improved the problem-solving success rate from 73% to 92.8%. This substantial performance boost highlights the model’s ability to mitigate errors that standard verifiers often overlook, particularly in complex reasoning scenarios. Furthermore, the researchers observed that the GenRM model scales effectively with increased dataset size and model capacity, further enhancing its applicability across various reasoning tasks.
In conclusion, the introduction of the GenRM method by researchers at Google DeepMind marks a significant advancement in generative AI, particularly in addressing the verification challenges associated with reasoning tasks. The GenRM model offers a more reliable and accurate approach to solving complex problems by unifying solution generation and verification into a single process. This method improves the accuracy of AI-generated solutions and enhances the overall reasoning process, making it a valuable tool for future AI applications across multiple domains. As generative AI continues to evolve, the GenRM approach provides a solid foundation for further research and development, particularly in areas where precision and reliability are crucial.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Here is a highly recommended webinar from our sponsor: ‘Building Performant AI Applications with NVIDIA NIMs and Haystack’
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link











{kind=link}