
















Modern AI is no longer powered by a single type of processor—it runs on a diverse ecosystem of specialized compute architectures, each making deliberate tradeoffs between flexibility, parallelism, and memory efficiency. While traditional systems relied heavily on CPUs, today’s AI workloads are distributed across GPUs for massive parallel computation, NPUs for efficient on-device inference, and TPUs designed specifically for neural network execution with optimized data flow.
Emerging innovations like Groq’s LPU further push the boundaries, delivering significantly faster and more energy-efficient inference for large language models. As enterprises shift from general-purpose computing to workload-specific optimization, understanding these architectures has become essential for every AI engineer.
In this article, we’ll explore some of the most common AI compute architectures and break down how they differ in design, performance, and real-world use cases.
Central Processing Unit (CPU)
The CPU (Central Processing Unit) remains the foundational building block of modern computing and continues to play a critical role even in AI-driven systems. Designed for general-purpose workloads, CPUs excel at handling complex logic, branching operations, and system-level orchestration. They act as the “brain” of a computer—managing operating systems, coordinating hardware components, and executing a wide range of applications from databases to web browsers. While AI workloads have increasingly shifted toward specialized hardware, CPUs are still indispensable as controllers that manage data flow, schedule tasks, and coordinate accelerators like GPUs and TPUs.
From an architectural standpoint, CPUs are built with a small number of high-performance cores, deep cache hierarchies, and access to off-chip DRAM, enabling efficient sequential processing and multitasking. This makes them highly versatile, easy to program, widely available, and cost-effective for general computing tasks.
However, their sequential nature limits their ability to handle massively parallel operations such as matrix multiplications, making them less suitable for large-scale AI workloads compared to GPUs. While CPUs can process diverse tasks reliably, they often become bottlenecks when dealing with massive datasets or highly parallel computations—this is where specialized processors outperform them. Crucially, CPUs are not replaced by GPUs; instead, they complement them by orchestrating workloads and managing the overall system.

Graphics Processing Unit (GPU)
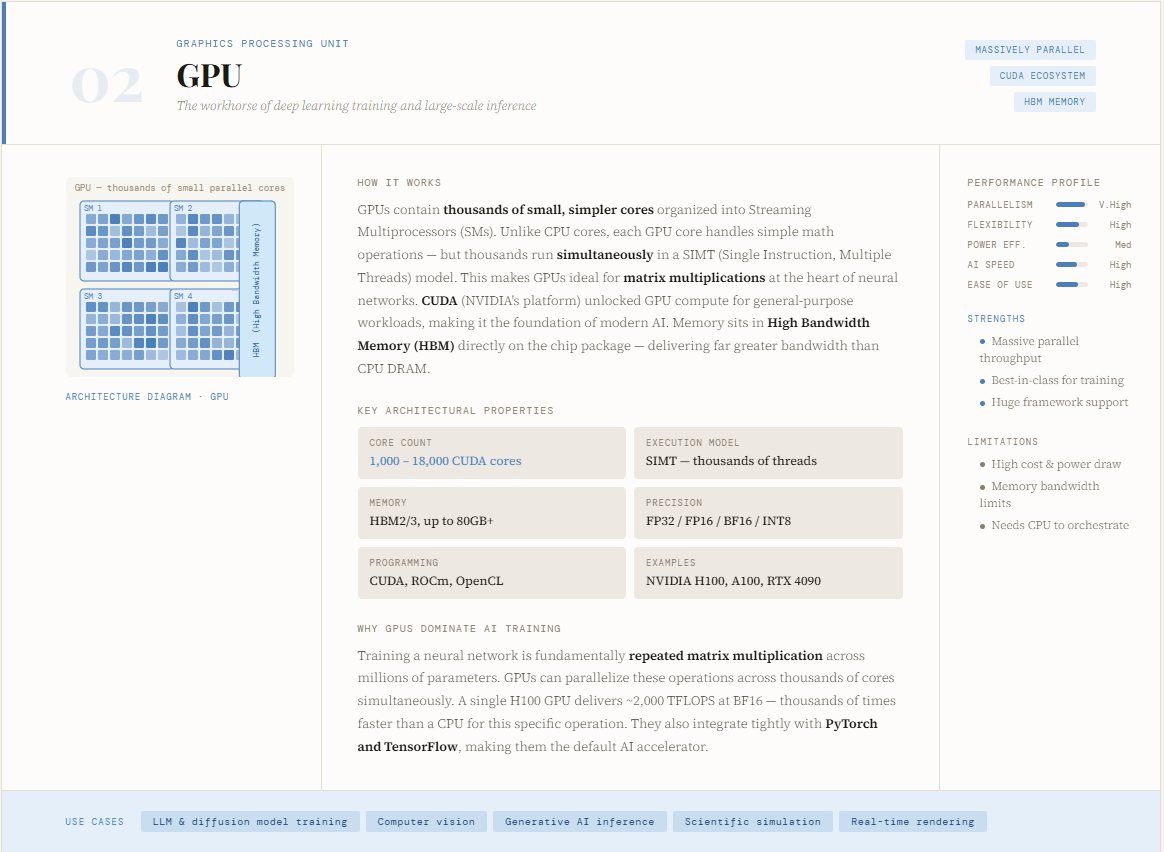
The GPU (Graphics Processing Unit) has become the backbone of modern AI, especially for training deep learning models. Originally designed for rendering graphics, GPUs evolved into powerful compute engines with the introduction of platforms like CUDA, enabling developers to harness their parallel processing capabilities for general-purpose computing. Unlike CPUs, which focus on sequential execution, GPUs are built to handle thousands of operations simultaneously—making them exceptionally well-suited for the matrix multiplications and tensor operations that power neural networks. This architectural shift is precisely why GPUs dominate AI training workloads today.
From a design perspective, GPUs consist of thousands of smaller, slower cores optimized for parallel computation, allowing them to break large problems into smaller chunks and process them concurrently. This enables massive speedups for data-intensive tasks like deep learning, computer vision, and generative AI. Their strengths lie in handling highly parallel workloads efficiently and integrating well with popular ML frameworks like Python and TensorFlow.
However, GPUs come with tradeoffs—they are more expensive, less readily available than CPUs, and require specialized programming knowledge. While they significantly outperform CPUs in parallel workloads, they are less efficient for tasks involving complex logic or sequential decision-making. In practice, GPUs act as accelerators, working alongside CPUs to handle compute-heavy operations while the CPU manages orchestration and control.
Tensor Processing Unit (TPU)
The TPU (Tensor Processing Unit) is a highly specialized AI accelerator designed by Google specifically for neural network workloads. Unlike CPUs and GPUs, which retain some level of general-purpose flexibility, TPUs are purpose-built to maximize efficiency for deep learning tasks. They power many of Google’s large-scale AI systems—including search, recommendations, and models like Gemini—serving billions of users globally. By focusing purely on tensor operations, TPUs push performance and efficiency further than GPUs, particularly in large-scale training and inference scenarios deployed via platforms like Google Cloud.
At the architectural level, TPUs use a grid of multiply-accumulate (MAC) units—often referred to as a matrix multiply unit (MXU)—where data flows in a systolic (wave-like) pattern. Weights stream in from one side, activations from another, and intermediate results propagate across the grid without repeatedly accessing memory, drastically improving speed and energy efficiency. Execution is compiler-controlled rather than hardware-scheduled, enabling highly optimized and predictable performance. This design makes TPUs extremely powerful for large matrix operations central to AI.
However, this specialization comes with tradeoffs: TPUs are less flexible than GPUs, rely on specific software ecosystems (like TensorFlow, JAX, or PyTorch via XLA), and are primarily accessible through cloud environments. In essence, while GPUs excel at parallel general-purpose acceleration, TPUs take it a step further—sacrificing flexibility to achieve unmatched efficiency for neural network computation at scale.

Neural Processing Unit (NPU)
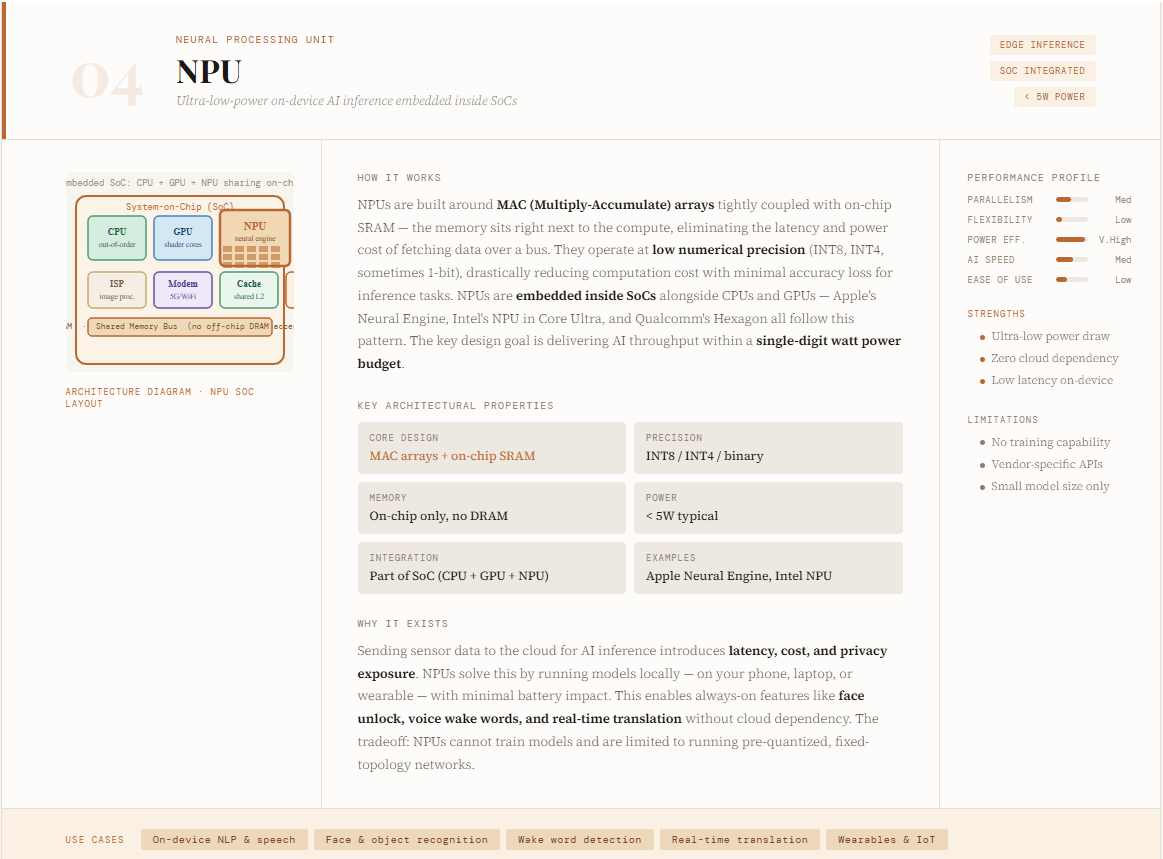
The NPU (Neural Processing Unit) is an AI accelerator designed specifically for efficient, low-power inference—especially at the edge. Unlike GPUs that target large-scale training or data center workloads, NPUs are optimized to run AI models directly on devices like smartphones, laptops, wearables, and IoT systems. Companies like Apple (with its Neural Engine) and Intel have adopted this architecture to enable real-time AI features such as speech recognition, image processing, and on-device generative AI. The core design focuses on delivering high throughput with minimal energy consumption, often operating within single-digit watt power budgets.
Architecturally, NPUs are built around neural compute engines composed of MAC (multiply-accumulate) arrays, on-chip SRAM, and optimized data paths that minimize memory movement. They emphasize parallel processing, low-precision arithmetic (like 8-bit or lower), and tight integration of memory and computation using concepts like synaptic weights—allowing them to process neural networks extremely efficiently. NPUs are typically integrated into system-on-chip (SoC) designs alongside CPUs and GPUs, forming heterogeneous systems.
Their strengths include ultra-low latency, high energy efficiency, and the ability to handle AI tasks like computer vision and NLP locally without cloud dependency. However, this specialization also means they lack flexibility, are not suited for general-purpose computing or large-scale training, and often depend on specific hardware ecosystems. In essence, NPUs bring AI closer to the user—trading off raw power for efficiency, responsiveness, and on-device intelligence.
Language Processing Unit (LPU)
The LPU (Language Processing Unit) is a new class of AI accelerator introduced by Groq, purpose-built specifically for ultra-fast AI inference. Unlike GPUs and TPUs, which still retain some general-purpose flexibility, LPUs are designed from the ground up to execute large language models (LLMs) with maximum speed and efficiency. Their defining innovation lies in eliminating off-chip memory from the critical execution path—keeping all weights and data in on-chip SRAM. This drastically reduces latency and removes common bottlenecks like memory access delays, cache misses, and runtime scheduling overhead. As a result, LPUs can deliver significantly faster inference speeds and up to 10x better energy efficiency compared to traditional GPU-based systems.
Architecturally, LPUs follow a software-first, compiler-driven design with a programmable “assembly line” model, where data flows through the chip in a deterministic, perfectly scheduled manner. Instead of dynamic hardware scheduling (like in GPUs), every operation is pre-planned at compile time—ensuring zero execution variability and fully predictable performance. The use of on-chip memory and high-bandwidth data “conveyor belts” eliminates the need for complex caching, routing, and synchronization mechanisms.
However, this extreme specialization introduces tradeoffs: each chip has limited memory capacity, requiring hundreds of LPUs to be connected for serving large models. Despite this, the latency and efficiency gains are substantial, especially for real-time AI applications. In many ways, LPUs represent the far end of the AI hardware evolution spectrum—moving from general-purpose flexibility (CPUs) to highly deterministic, inference-optimized architectures built purely for speed and efficiency.

Comparing the different architectures
AI compute architectures exist on a spectrum—from flexibility to extreme specialization—each optimized for a different role in the AI lifecycle. CPUs sit at the most flexible end, handling general-purpose logic, orchestration, and system control, but struggle with large-scale parallel math. GPUs move toward parallelism, using thousands of cores to accelerate matrix operations, making them the dominant choice for training deep learning models.
TPUs, developed by Google, go further by specializing in tensor operations with systolic array architectures, delivering higher efficiency for both training and inference in structured AI workloads. NPUs push optimization toward the edge, enabling low-power, real-time inference on devices like smartphones and IoT systems by trading off raw power for energy efficiency and latency. At the far end, LPUs, introduced by Groq, represent extreme specialization—designed purely for ultra-fast, deterministic AI inference with on-chip memory and compiler-controlled execution.
Together, these architectures are not replacements but complementary components of a heterogeneous system, where each processor type is deployed based on the specific demands of performance, scale, and efficiency.


I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.
Credit: Source link









 2026 Q1 – Results – Earnings Call Presentation (OTCMKTS:TDVXF) 2026-04-25")

{kind=link}