
















Most end-to-end OCR models slow down as output grows. Each generated token adds to the KV cache. Memory rises and generation drags. Parsing dozens of pages becomes impractical. Baidu’s Unlimited OCR addresses this directly. It swaps the decoder’s attention for a design that keeps memory constant.
TL;DR
- Unlimited OCR is a 3B-parameter Mixture-of-Experts model, with only 500M parameters active.
- It replaces decoder attention with Reference Sliding Window Attention (R-SWA), keeping the KV cache constant.
- The model parses dozens of pages in one forward pass under a 32K maximum length.
- It scores 93.23 on OmniDocBench v1.5, beating the DeepSeek OCR baseline by 6.22 points.
- It builds on DeepSeek OCR via continue-training, not a from-scratch run.
What is Unlimited OCR?
Unlimited OCR takes DeepSeek OCR as its baseline. It keeps the DeepEncoder and the Mixture-of-Experts decoder. The MoE design holds 3B total parameters but activates only 500M at inference.
The DeepEncoder is the compression engine. It cascades a SAM-ViT under window attention with a CLIP-ViT under global attention. At the bridge, it applies 16× token compression. A 1024×1024 PDF image becomes just 256 visual tokens. Fewer input tokens mean a smaller prefill.
DeepEncoder natively supports five resolution modes, and Unlimited OCR keeps two. ‘Base’ mode runs at 1024×1024 for multi-page work. ‘Gundam’ mode uses dynamic resolution for single pages.
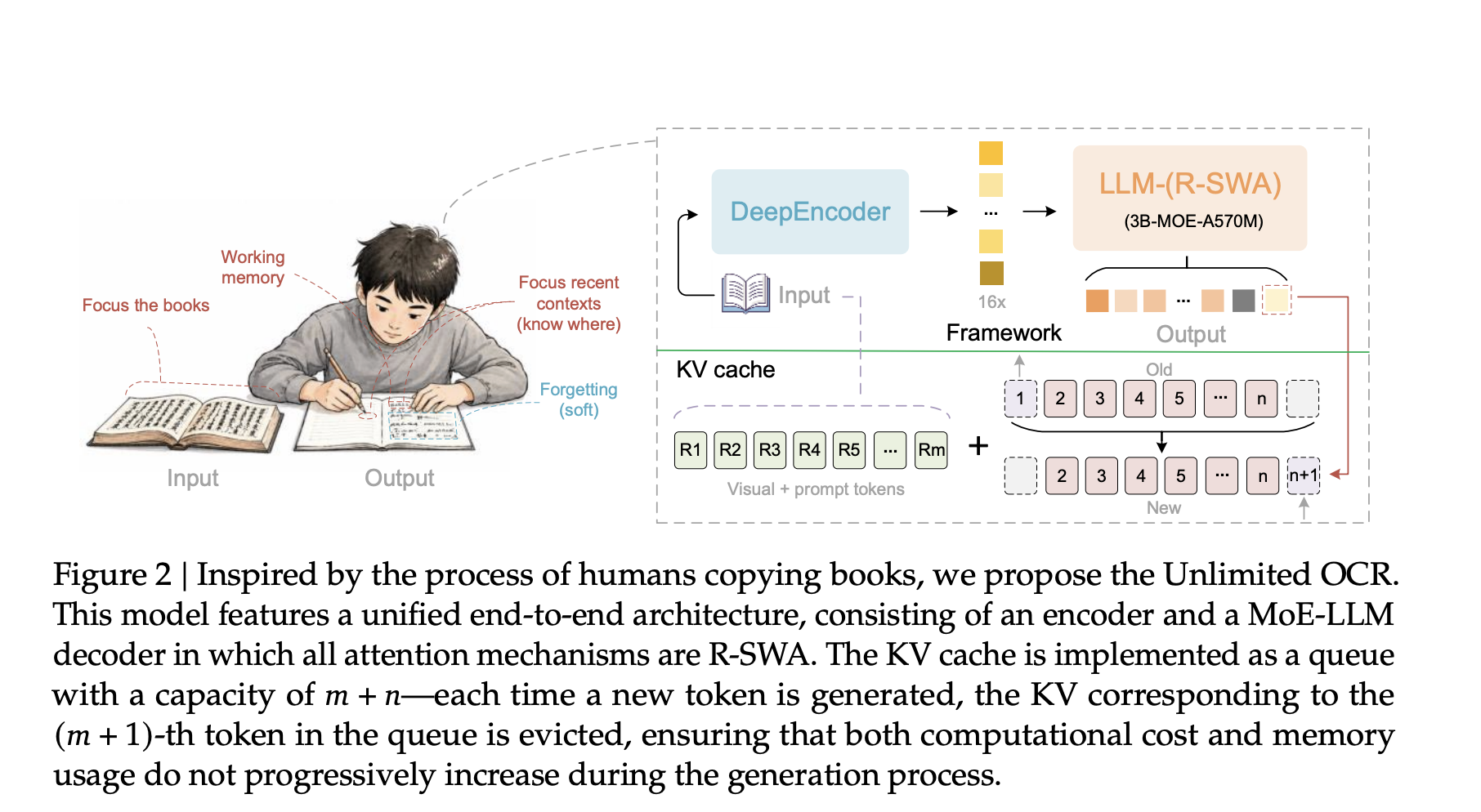
How R-SWA Keeps the Cache Constant
The contribution is Reference Sliding Window Attention. Standard Multi-Head Attention stores a key and value for every token. As output length T grows, the cache grows with it. The size is CMHA(T) = Lm + T. Memory and latency climb without bound.
R-SWA breaks that link. Each generated token attends to all reference tokens, meaning the visual tokens and the prompt. It also attends to the preceding n output tokens, where n defaults to 128. Everything older is evicted. The cache becomes a fixed queue of size m + n.
The size is CR-SWA(T) = Lm + min(n, T) ≤ Lm + n. It is bounded by a constant. As T grows far beyond n, the cache ratio trends toward zero. So memory stays flat and per-step latency stays flat.
The research team compare this to soft forgetting. A person copying a book glances at the source and the last few words. They do not re-read everything transcribed so far. Visual tokens never undergo state updates. That avoids the progressive blurring seen in linear attention. The interactive simulator below lets you vary T and watch both caches respond.
How It Was Trained
Unlimited OCR was not trained from scratch. The research team continue-trained from the DeepSeek OCR checkpoint for 4,000 steps. They froze the DeepEncoder and trained only the decoder. Training used about 2M document samples on 8×16 A800 GPUs. The 9:1 split favored single-page data, with multi-page samples built by concatenation.
Benchmark
The research team evaluates on OmniDocBench v1.5 and v1.6. The main finding/stat is 93.23 overall on v1.5. That beats the DeepSeek OCR baseline by 6.22 points. The table below compares the three related models. All three share the same 3B-A0.5B size.
| Metric (v1.5) | DeepSeek-OCR | DeepSeek-OCR 2 | Unlimited-OCR |
|---|---|---|---|
| Overall ↑ | 87.01 | 89.17 | 93.23 |
| Text Edit ↓ | 0.073 | 0.049 | 0.038 |
| Formula CDM ↑ | 83.37 | 86.85 | 92.61 |
| Table TEDS ↑ | 84.97 | 85.60 | 90.93 |
| Read-order Edit ↓ | 0.086 | 0.060 | 0.045 |
On OmniDocBench v1.6, Unlimited OCR reaches 93.92 overall. That is the top score in the research paper’s v1.6 comparison. Gains hold across text, formula, and table recognition.
Speed improves too. On OmniDocBench in Base mode, Unlimited OCR hits 5,580 TPS against DeepSeek OCR’s 4,951 TPS. That is a 12.7% increase. The gap widens with longer output. At a 6,000-token output ceiling, DeepSeek OCR lags Unlimited OCR by 35%.
Where It Fits: Use Cases
The constant cache suits workloads that page-by-page systems handle poorly.
- Whole-book transcription: Feed 40+ pages and parse them in one continuous pass. The reported edit distance stays below 0.11 at 40+ pages, with 96.90% Distinct-35.
- Document parsing pipelines: Extract text, tables, formulas, and reading order in a single forward pass.
- High-throughput batch parsing: The included
infer.pylaunches an SGLang server and sends concurrent requests over a folder or PDF. - Beyond OCR: The research team call R-SWA a general parsing attention, applicable to ASR and translation.
Running It: Minimal Code
The Transformers path needs trust_remote_code=True and a CUDA GPU. Single-image parsing uses Gundam mode.
import torch
from transformers import AutoModel, AutoTokenizer
name = "baidu/Unlimited-OCR"
tokenizer = AutoTokenizer.from_pretrained(name, trust_remote_code=True)
model = AutoModel.from_pretrained(
name, trust_remote_code=True, use_safetensors=True,
torch_dtype=torch.bfloat16,
).eval().cuda()
model.infer(
tokenizer,
prompt="document parsing.",
image_file="your_image.jpg",
output_path="your/output/dir",
base_size=1024, image_size=640, crop_mode=True, # gundam mode
max_length=32768,
no_repeat_ngram_size=35, ngram_window=128,
save_results=True,
) Multi-page and PDF parsing call model.infer_multi in Base mode at image_size=1024. For production throughput, SGLang serves an OpenAI-compatible API using the fa3 attention backend.
Strengths and Weaknesses
Strengths:
- Constant KV cache holds memory and latency flat across long outputs.
- End-to-end SOTA scores on OmniDocBench v1.5 and v1.6.
- Only 500M active parameters keep inference cheap.
- MIT license, open weights, and dual Transformers plus SGLang support.
- R-SWA gains arrive without a measured accuracy cost on single pages.
Weaknesses:
- Parsing is not truly unlimited; a 32K context still bounds the prefill.
- Long prefills grow as page count accumulates, despite heavy compression.
- Multi-page runs use Base mode only, so very small text can be missed.
- ASR and translation transfer remains future work, not a shipped result.
Check out the Paper, Repo and Model Weights. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
Credit: Source link











{kind=link}