
















































The rapid scaling of diffusion models has led to memory usage and latency challenges, hindering their deployment, particularly in resource-constrained environments. Such models have manifested impressive ability in rendering highly-fidelity images but are demanding in both memory and computation, which limits their availability in consumer-grade devices and applications that require low latencies. Therefore, these challenges need to be addressed to make it feasible to train large-scale diffusion models across a vast multiplicity of platforms in real time.
Current techniques to solve memory and speed issues of diffusion models include post-training quantization and quantization-aware training mainly with weight-only quantization methods such as NormalFloat4 (NF4). While these methods work well for language models, they fall short for diffusion models because of a higher computational requirement. Unlike language models, diffusion models require simultaneous low-bit quantization of both weights and activations to prevent performance degradation. The existing methods for quantization suffer due to the presence of outliers in both weights and activations at 4-bit precision accuracy and contribute towards compromised visual quality along with computational inefficiencies, making a case for a more robust solution.
Researchers from MIT, NVIDIA, CMU, Princeton, UC Berkeley, SJTU, and Pika Labs propose SVDQuant. This quantization paradigm introduces a low-rank branch to absorb outliers, facilitating effective 4-bit quantization for diffusion models. Using creative SVD to deal with the outliers, SVDQuant would transfer it across from activations to weight and then absorb it into a low-rank branch which allows residual to be quantized at 4 bit without loss in performance and avoid one common error related to the outliers further optimization of the process of quantization without overhead re-quantization. The scientists developed an inference engine called Nunchaku that combines low-rank and low-bit computation kernels with memory access optimization to cut latency.
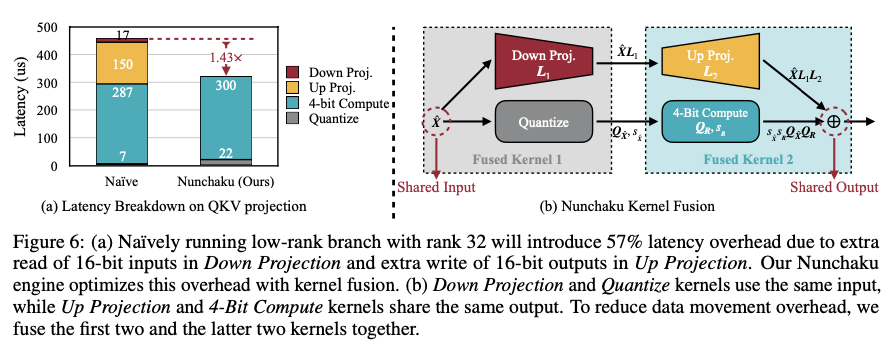
SVDQuant works by smoothing and sending outliers from activations to weights. Then applying SVD decomposition over weights, split the weights into a low rank and residual. The low-rank component would suck in the outliers at 16-bit precision while the residual gets quantized at 4-bit precision. The Nunchaku inference engine further optimizes this by allowing the low-rank and the low-bit branches together, thereby merging the input and output dependencies, which results in reduced memory access and subsequently reduced latency. Impressively, evaluations on models such as FLUX.1 and SDXL, using datasets like MJHQ and sDCI, reveal huge memory savings of 3.5× and latency savings of up to 10.1× on laptop devices. For instance, applying SVDQuant reduces the 12 billion parameter FLUX.1 model from 22.7 GB down to 6.5 GB, avoiding CPU offloading in memory-constrained settings.
The SVDQuant surpassed the state-of-the-art quantization methods both in efficiency and visual fidelities. For 4-bit quantization, SVDQuant constantly shows great perceptual similarity accompanied with high-quality numerical constructs that can be preserved for any image generation task throughout with a consistent outperforming of competitors, such as NF4, concerning their Fréchet Inception Distance, ImageReward, LPIPS, and PSNR scores across multiple diffusion model architectures and for example, compared to the FLUX.1-dev model, SVDQuant’s configuration is well tuned at LPIPS scores aligned closely with the 16-bit baseline while saving 3.5× in model size and achieving around a 10.1× speedup on GPU devices without having CPU offloading. Such efficiency supports the real-time generation of high-quality images on memory-limited devices underlines the effective practical deployment of large diffusion models.

In conclusion, the proposed approach SVDQuant employs advanced 4-bit quantization; here, the outlier problems found in the diffusion model are coped with while maintaining the quality of the images, with significant reductions in memory and latency. Optimizing quantization and eliminating redundant data movement by the Nunchaku inference engine forms a foundation for the efficient deployment of large diffusion models and, thus, propels their potential use in real-world interactive applications on consumer hardware.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.
Credit: Source link









{kind=link}