
















Generating code with execution feedback is difficult because errors often require multiple corrections, and fixing them in a structured way is not simple. Training models to learn from execution feedback is necessary but approaches face challenges. Some methods attempt to correct errors in a single step but fail when multiple refinements are needed. Others use complex learning techniques to optimize long-term improvements. Still, these methods struggle with weak learning signals, making training slow and inefficient—the lack of an effective method for handling iterative corrections results in unstable learning and poor performance.
Currently, prompting-based systems try to solve multi-step tasks using self-debugging, test generation, and reflection but improve only slightly. Some methods train reward models like CodeRL for fixing errors and ARCHER for structured decision-making, while others use Monte Carlo Tree Search (MCTS) but require too much computation. Verifier-based approaches, like “Let’s Verify Step by Step” and AlphaCode, help find mistakes or create test cases, but some models rely only on syntax checks, which are not enough for proper training. Score limits training steps, and RISE uses complex corrections, making learning inefficient. Fine-tuned agents like FireAct, LEAP and feedback-based models like RL4VLM and GLAM try to improve performance. However, current techniques either fail to refine code properly over multiple steps or are too unstable and inefficient.
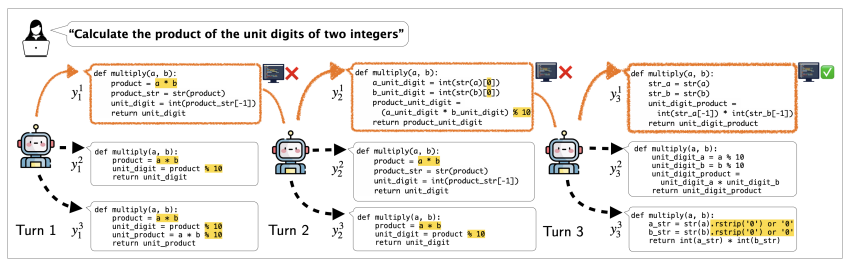
To mitigate these issues, researchers proposed µCODE, a multi-turn code generation method that improves using execution feedback. Existing approaches face challenges with execution errors and reinforcement learning complexity, but µCODE overcomes these by following an expert iteration framework with a local search expert. A verifier assesses code quality, while a generator learns from the best solutions, refining its output over multiple iterations. During inference, a Best-of-N search strategy helps generate and improve code based on execution results, ensuring better performance.
The framework first trains a verifier through supervised learning to score code snippets, making evaluations more reliable. Binary Cross-Entropy predicts correctness, while Bradley-Terry ranks solutions for better selection. The generator then learns iteratively by relabeling past outputs with expert-selected solutions, improving accuracy. Multiple solutions are produced at inference, and the verifier selects the best, refining outputs until all tests pass. By treating code generation as an imitation learning problem, µCODE eliminates complex exploration and enables efficient optimization.
Researchers evaluated µCODE’s effectiveness by comparing it with state-of-the-art methods, analyzing the impact of the learned verifier during training and inference, and assessing different loss functions for verifier training. The generator was initialized using Llama models, and experiments were conducted on MBPP and HumanEval datasets. The training was performed on MBPP’s training set, with evaluations on its test set and HumanEval. Comparisons included single-turn and multi-turn baselines such as STaR and Multi–STaR, where fine-tuning was based on correctly generated solutions. Performance was measured using Best-of-N (BoN) accuracy, with the verifier ranking candidate solutions at each turn.
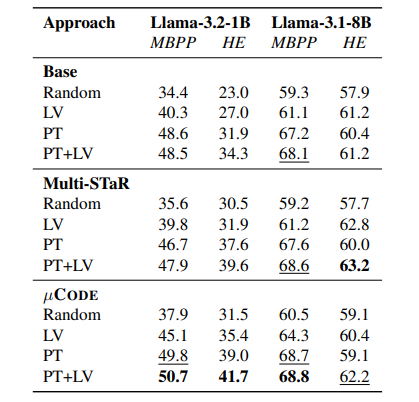
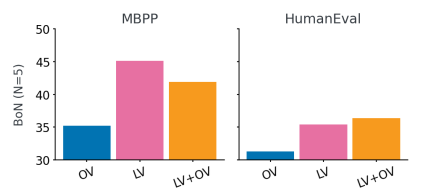
Results indicated that multi-turn approaches performed better than single-turn methods, highlighting the benefits of execution feedback. µCODE outperformed Multi-STaR, achieving a 1.9% improvement on HumanEval with a 1B model. Bon search further enhanced performance, with µCODE showing a 12.8% gain over greedy decoding. The learned verifier (LV) improved training outcomes, surpassing oracle verifiers (OV) alone. Further analysis showed that the learned verifier helped select better solutions during inference, particularly in the absence of public tests. Inference-time scaling revealed diminishing performance gains beyond a certain number of candidate solutions. A hierarchical verification strategy (PT+LV) integrating public test results with learned verifier scores provided the highest performance, showing the effectiveness of the verifier in eliminating erroneous solutions and making iterative predictions.
In conclusion, the proposed µCODE framework provides a scalable approach to multi-turn code generation using single-step rewards and a learned verifier for iterative improvement. Results indicate µCODE performs better than oracle-based approaches, producing more precise code. Though constrained by model size, dataset size, and Python focus, it can be a solid baseline for future work. Expanding training data, scaling to larger models, and applying it to multiple programming languages can further enhance its effectiveness.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.
🚨 Meet Parlant: An LLM-first conversational AI framework designed to provide developers with the control and precision they need over their AI customer service agents, utilizing behavioral guidelines and runtime supervision. 🔧 🎛️ It’s operated using an easy-to-use CLI 📟 and native client SDKs in Python and TypeScript 📦.
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.
Credit: Source link











{kind=link}