














































In the ever-evolving field of artificial intelligence, the pursuit of large-scale deep-learning models capable of handling complex tasks has been at the forefront. These models, often powered by billions of parameters, have demonstrated remarkable capabilities in various applications, from natural language understanding to computer vision. However, there’s a catch – building and training such colossal models traditionally demands astronomical costs and substantial computational resources, often rendering them inaccessible to smaller companies, independent developers, and researchers. Enter Colossal-AI, a pioneering research team committed to democratizing access to large models through innovative training techniques.
The problem is the exorbitant cost of training large-scale deep-learning models from scratch. Conventional approaches necessitate vast amounts of data, computational power, and financial resources. This prohibitive barrier to entry has long discouraged many from venturing into the realm of large models. It’s not uncommon for industry insiders to humorously refer to this domain as reserved only for those with “50 million dollars” to spare. This situation has stifled innovation and limited the accessibility of state-of-the-art AI models.
Colossal-AI’s groundbreaking solution comes from Colossal-LLaMA-2, an innovative approach to training large models that defies convention. Unlike traditional methods that consume trillions of data tokens and incur astronomical costs, Colossal-LLaMA-2 achieves remarkable results with just a few hundred dollars. This approach opens up the possibility of constructing large models from scratch without breaking the bank.
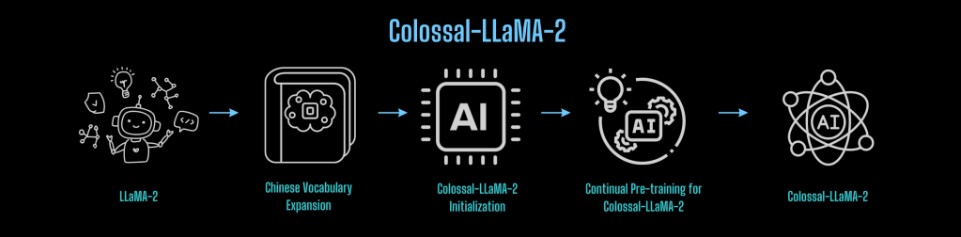
The success of Colossal-LLaMA-2 can be attributed to several key strategies. Firstly, the research team expanded the model’s vocabulary significantly. This expansion improved the efficiency of encoding string sequences and enriched the encoded sequences with more meaningful information, enhancing document-level encoding and understanding. However, the team was careful to maintain the vocabulary, as an excessively large vocabulary would increase the number of embedding-related parameters, impacting training efficiency.
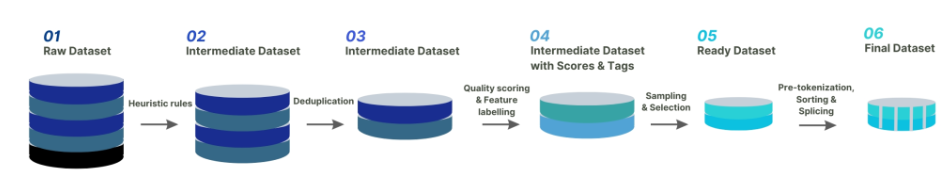
To further reduce training costs and enhance efficiency, high-quality data played a crucial role. The team developed a complete data cleaning system and toolkit for selecting higher-quality data for continual pre-training. This approach stimulated the model’s capabilities and addressed the issue of catastrophic forgetting.
Colossal-LaMA-2′s training strategy is another critical component of its success. It utilizes a multi-stage, hierarchical, continual pre-training scheme that progresses in three stages: large-scale pre-training, Chinese knowledge injection, and relevant knowledge replay. This approach ensures that the model evolves effectively in Chinese and English, making it versatile and capable of handling a wide range of tasks.
Data distribution balance is paramount in continual pre-training, and to achieve this, the team designed a data bucketing strategy, dividing the same type of data into ten different bins. This ensures that the model can utilize every kind of data evenly.
Performance is assessed comprehensively through the ColossalEval framework, which evaluates large language models from various dimensions, including knowledge reserve capability, multiple-choice questions, content generation, and more. Colossal-LaMA-2 consistently outperforms its competitors in these evaluations, showcasing its robustness and versatility.
In conclusion, Colossal-LLaMA-2 represents a remarkable breakthrough in large-scale deep-learning models. By drastically reducing training costs and enhancing accessibility, it brings the power of state-of-the-art models to a wider audience. The implications of this advancement are profound. Smaller companies, independent developers, and researchers are now facing insurmountable barriers when it comes to leveraging the capabilities of large models. This democratization of AI has the potential to spark innovation across various domains and accelerate the development and deployment of AI applications.
Check out the Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 31k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.

Credit: Source link










{kind=link}