
















































Large Language Models (LLMs) have revolutionized long-context question answering (LCQA), a complex task requiring reasoning over extensive documents to provide accurate answers. While recent long-context LLMs like Gemini and GPT4-128k can process entire documents directly, they struggle with the “lost in the middle” phenomenon, where relevant information in the middle of documents often leads to suboptimal or incorrect responses. Retrieval-Augmented Generation (RAG) systems attempt to address this by using fixed-length chunking strategies, but they face their own limitations. These include the disruption of contextual structure, incomplete information in chunks, and challenges with low evidence density in long documents, where noise can impair the LLMs’ ability to identify key information accurately. These issues collectively hinder the development of reliable LCQA systems.
Multiple approaches have emerged to address the challenges in long-context question answering. Long-context LLM methods fall into two categories: training-based approaches like Position Interpolation, YaRN, and LongLoRA, which offer better performance but require significant resources, and non-fine-tuned methods such as restricted attention and context compression, which provide plug-and-play solutions at lower costs. Traditional RAG systems attempted to improve LLMs’ response quality by utilizing external knowledge sources, but their direct incorporation of retrieved chunks led to incomplete information and noise. Advanced RAG models introduced solutions like filtering retrieved knowledge, implementing chunk-free strategies to preserve semantics, and employing active retrieval mechanisms. Domain-specific fine-tuning has also emerged as a strategy to enhance RAG components, focusing on improving retrieval outcomes and generating more personalized outputs.
Researchers from Institute of Information Engineering, Chinese Academy of Sciences, School of Cyber Security, University of Chinese Academy of Sciences, Tsinghua University and Zhipu AI introduce LongRAG, a comprehensive solution to LCQA challenges through a dual-perspective, robust system paradigm comprising four plug-and-play components: a hybrid retriever, an LLM-augmented information extractor, a CoT-guided filter, and an LLM-augmented generator. The system’s innovative approach addresses both global context understanding and factual detail identification. The long-context extractor employs a mapping strategy to transform retrieved chunks into a higher-dimensional semantic space, preserving contextual relationships, while the CoT-guided filter utilizes Chain of Thought reasoning to provide global clues and precisely filter irrelevant information. This dual-perspective approach significantly enhances the system’s ability to process complex, lengthy contexts while maintaining accuracy. The system’s architecture is complemented by an automated instruction data pipeline for fine-tuning, enabling strong “instruction-following” capabilities and easy domain adaptation.
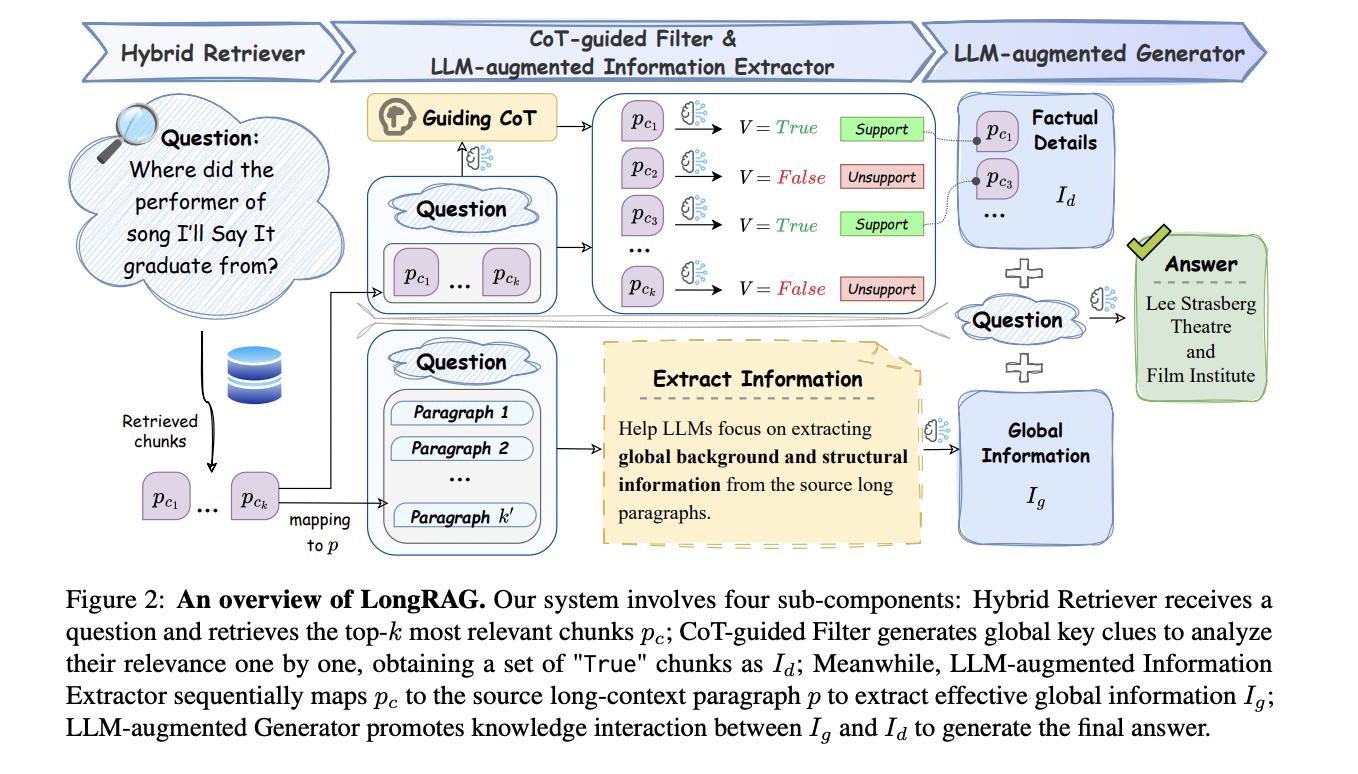
LongRAG’s architecture consists of four sophisticated components working in harmony. The hybrid retriever employs a dual-encoder structure with sliding windows for chunk segmentation, combining coarse-grained rapid retrieval with fine-grained semantic interaction through FAISS implementation. The LLM-augmented information extractor addresses scattered evidence by mapping retrieved chunks back to source paragraphs using a mapping function, preserving semantic order and contextual relationships. The CoT-guided filter implements a two-stage strategy: first generating Chain of Thought reasoning with a global perspective, then using these insights to evaluate and filter chunks based on their relevance to the question. Finally, the LLM-augmented generator synthesizes the global information and filtered factual details to produce accurate answers. The system’s effectiveness is enhanced through instruction-tuning using 2,600 high-quality data points from LRGinstruction, with models trained using advanced strategies like DeepSpeed and flash attention.
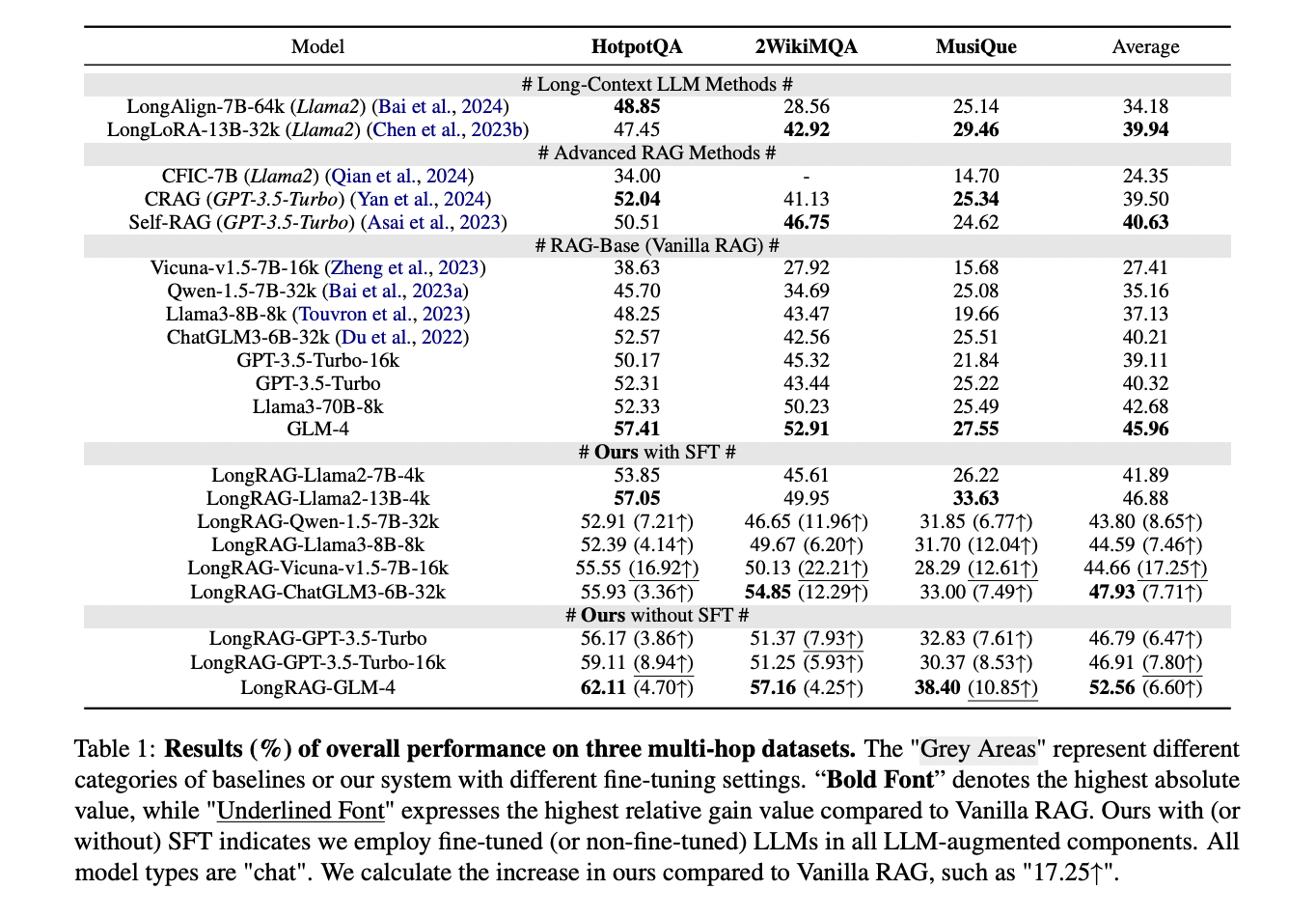
LongRAG demonstrates superior performance across multiple comparative dimensions. When compared to long-context LLM methods like LongAlign and LongLoRA, the system achieves higher performance across all datasets, particularly in detecting crucial factual details that other models often miss in mid-document sections. Compared to advanced RAG systems, LongRAG shows a 6.16% improvement over leading competitors like Self-RAG, primarily due to its more robust handling of factual details and complex multi-hop questions. The system’s most dramatic improvement appears in comparison to Vanilla RAG, showing up to a 17.25% performance increase, attributed to its superior preservation of coherent long-context background and structure. Notably, LongRAG’s effectiveness extends across both small and large language models, with fine-tuned ChatGLM3-6B-32k outperforming even non-fine-tuned GPT-3.5-Turbo, demonstrating the system’s robust architecture and effective instruction-following capabilities.
LongRAG emerges as a robust solution in the field of long-context question answering through its innovative dual information perspective approach. The system effectively addresses two critical challenges that have plagued existing methods: the incomplete collection of long-context information and the imprecise identification of factual information in noisy environments. Through comprehensive multidimensional experiments, LongRAG demonstrates not only superior performance over long-context LLMs, advanced RAG methods, and Vanilla RAG but also remarkable cost-effectiveness. The system’s plug-and-play components achieve better results than GPT-3.5-Turbo while using smaller parameter-size LLMs, making it a practical solution for local deployment without relying on expensive API resources.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link










{kind=link}