














































Large language models (LLMs) have made important advances in artificial intelligence, with superior performance on various tasks as their parameters and training data grow. GPT-3, PaLM, and Llama-3.1 perform well in many applications with billions of parameters. However, when implemented in low-power platforms, scaling LLMs poses severe difficulties regarding training and inference queries. While it was still experimental and rare, scaling proved efficient in reaching a larger number of people over time, and as the process progressed, it became very unsustainable. It is also necessary to enable the possibility of applying LLMs on devices with little computational power to address more fundamental aspects of reasoning and produce more tokens.
Current methods for optimizing large language models comprise scaling, pruning, distillation, and quantization. Scaling enhances performance by increasing parameters but demands higher resources. Pruning removes less critical model components to reduce size but often sacrifices performance. Distillation trains smaller models to replicate larger ones but typically results in lower density. Quantization reduces numerical precision for efficiency but may degrade results. These methods fail to balance efficiency and performance well, so there is a shift toward optimizing “density” as a more sustainable metric for developing large language models.
To solve this, researchers from Tsinghua University and ModelBest Inc. proposed the concept of “Capability density” as a new metric to evaluate the quality of LLMs across different scales and describe their trends in terms of effectiveness and efficiency. The density of Large Language Models (LLMs) is the ratio of effective parameter size to actual parameter size. The effective parameter size represents the number of parameters needed by a reference model to match the performance of a given model. This is estimated using the Scaling Law in two steps: (1) fitting a function between parameter size and language model loss and (2) predicting downstream task performance using a sigmoid function. The effective parameter size is computed after fitting loss and performance. Model density is calculated as the ratio of effective parameter size to actual size, where higher density suggests better performance per parameter. It is a very useful concept for optimizing models, mainly for deployment on resource-limited devices.
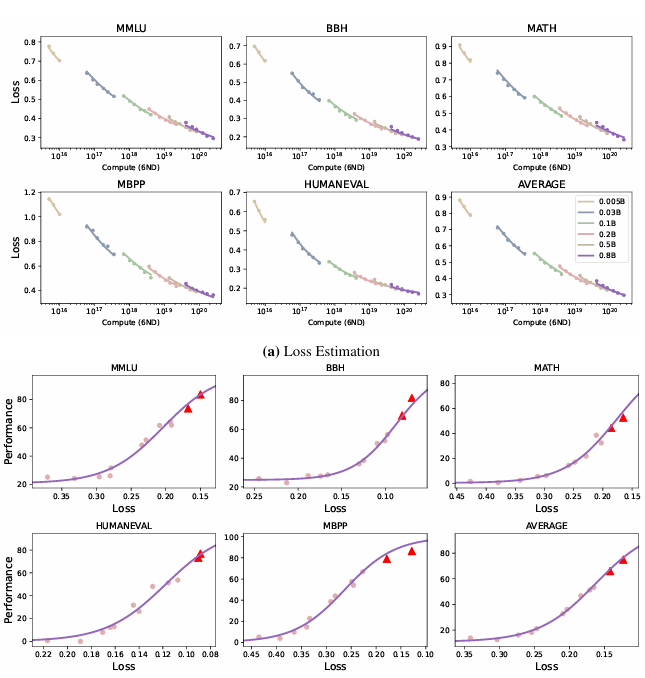
Researchers analyzed 29 open-source pre-trained models and evaluated the performance of large language models (LLMs) on various datasets, including MMLU, BBH, MATH, HumanEval, and MBPP, under few-shot settings like 5-shot, 3-shot, and 0-shot, utilizing open-source tools for benchmarking. The models were trained with varying parameter sizes, token lengths, and data scales, applying techniques such as chain-of-thought prompting and different learning rate schedulers. The performance scaling curves were obtained by training models on different token sizes, with models like Llama, Falcon, MPT, Phi, Mistral, and MiniCPM being tested across various configurations. Over time, the density of these models increased significantly, with newer models, such as MiniCPM-3-4B, achieving higher densities than older models. A linear regression model indicated that the LLM density doubles approximately every 95 days. This means that designs with more modest capabilities and lower costs will soon be able to compete with bigger, more complicated models, and technological advances will open the way to even more efficient designs.
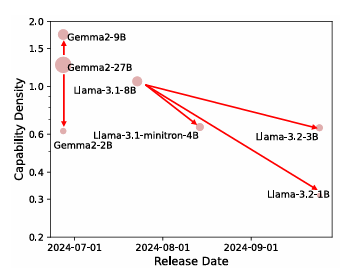
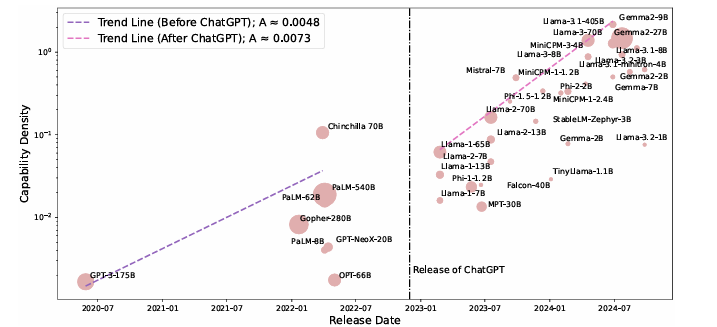
In conclusion, the proposed method highlighted exponentially increasing capability density in LLMs by showing rapid development and efficiency improvements. The evaluation results on some widely used LLM benchmarks indicated that the density of LLMs doubles every three months. Researchers also proposed the shift towards inference FLOPs for evaluating density by considering deeper reasoning. This method can be used for upcoming research and can be a turning point in the domain of LLMs!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 [Must Subscribe]: Subscribe to our newsletter to get trending AI research and dev updates
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.
Credit: Source link











{kind=link}