














































One intriguing aspect of human cognition is the process of logical deduction, where conclusions are derived from a set of premises or facts. The logical structure dictates that the order of premises should not influence the outcome of reasoning – a principle that holds in human cognitive processes to a large extent. However, in AI, this problem arises in LLMs: their performance significantly varies with changes in the sequence of presented premises despite the logical conclusion remaining unchanged.
Existing research highlights that the premise order effect in LLMs is connected to failure modes such as the reversal curse, distractibility, and limited logical reasoning capability. Including irrelevant context in the problem statement leads to a performance drop in LLMs, indicating distractibility. This means that language models can somewhat understand permuted texts, but LLM reasoning performance is highly sensitive to the ordering of premises.
Researchers from Google Deepmind and Stanford University have introduced a novel approach to figuring out the impact of premise ordering on LLM reasoning performance. By altering the sequence of premises in logical and mathematical reasoning tasks, the study systematically assesses the models’ ability to maintain accuracy. The findings are stark: a deviation from the optimal order can lead to a performance drop of over 30%, highlighting a previously underexplored aspect of model sensitivity.
The premise order effect is measured by varying the number of rules required in the proof and the number of distracting rules. The benchmark includes 27K problems with different premise orders and numbers of distracting rules. The R-GSM dataset was constructed to assess the effect of premise orders beyond logical reasoning in grade school math word problems. The R-GSM benchmark contains 220 pairs of problems with different orderings of problem statements. LLMs perform considerably worse on rewritten problems in the R-GSM benchmark. An example in R-GSM shows LLMs correctly solving the original problem but failing on the rewritten one.
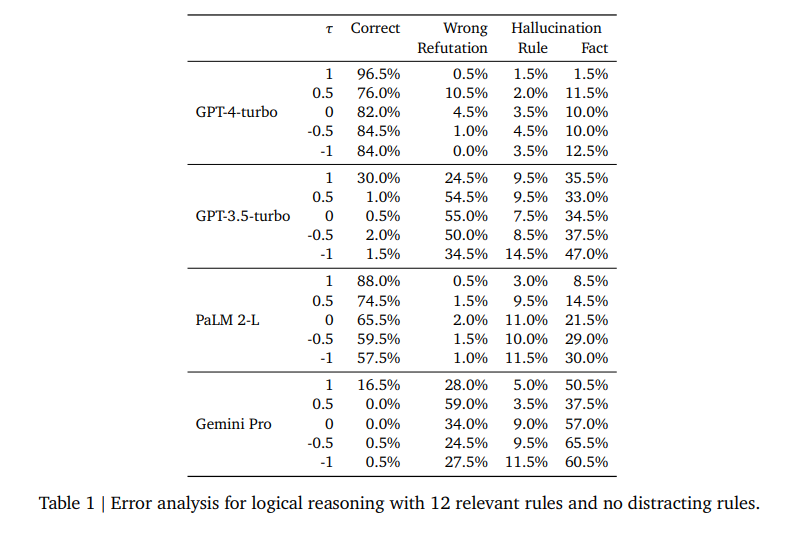
The study found that the performance of LLMs in reasoning tasks is significantly influenced by the order of presented premises, with a forward order yielding the best results. Variations in preference for premise order were observed among different LLMs, notably with GPT-4-turbo and PaLM 2-L. The presence of distracting rules further impacts reasoning performance, exacerbating the challenge. The R-GSM dataset demonstrated a general decline in LLM accuracy, particularly with reordered problems, highlighting issues such as fact hallucination and errors arising from sequential processing and overlooked temporal order.
In conclusion, the study critically examines the premise ordering effect, shedding light on an area of LLM performance that mirrors human cognitive biases yet deviates in its impact on reasoning accuracy. By addressing this limitation, the path forward involves refining AI’s reasoning capabilities to better align with human thought processes’ fluid and dynamic nature, ultimately leading to more versatile and reliable models capable of navigating the complexities of real-world reasoning tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link











{kind=link}