














































Advancements in multimodal intelligence depend on processing and understanding images and videos. Images can reveal static scenes by providing information regarding details such as objects, text, and spatial relationships. However, this comes at the cost of being extremely challenging. Video comprehension involves tracking changes over time, among other operations, while ensuring consistency across frames, requiring dynamic content management and temporal relationships. These tasks become tougher because the collection and annotation of video-text datasets are relatively difficult compared to the image-text dataset.
Traditional methods for multimodal large language models (MLLMs) face challenges in video understanding. Approaches like sparsely sampled frames, basic connectors, and image-based encoders fail to effectively capture temporal dependencies and dynamic content. Techniques such as token compression and extended context windows struggle with long-form video complexity, while integrating audio and visual inputs often lacks seamless interaction. Efforts in real-time processing and scaling model sizes remain inefficient, and existing architectures are not optimized for handling long video tasks.
To address video understanding challenges, researchers from Alibaba Group proposed the VideoLLaMA3 framework. This framework incorporates Any-resolution Vision Tokenization (AVT) and Differential Frame Pruner (DiffFP). AVT improves upon traditional fixed-resolution tokenization by enabling vision encoders to process variable resolutions dynamically, reducing information loss. This is achieved by adapting ViT-based encoders with 2D-RoPE for flexible position embedding. To preserve vital information, DiffFP deals with redundant and long video tokens by pruning frames with minimal differences as taken through a 1-norm distance between the patches. Dynamic resolution handling, in combination with efficient token reduction, improves the representation while reducing the costs.
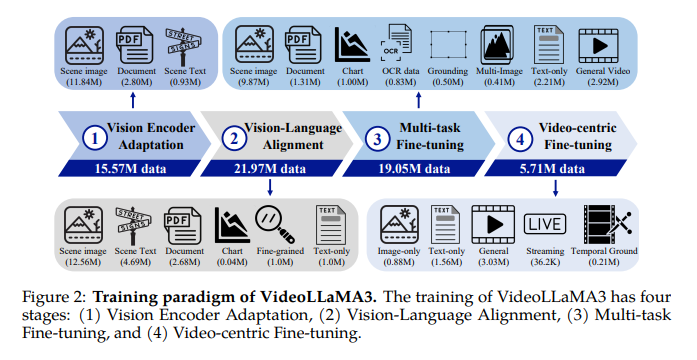
The model consists of a vision encoder, video compressor, projector, and large language model (LLM), initializing the vision encoder using a pre-trained SigLIP model. It extracts visual tokens, while the video compressor reduces video token representation. The projector connects the vision encoder to the LLM, and Qwen2.5 models are used for the LLM. Training occurs in four stages: Vision Encoder Adaptation, Vision-Language Alignment, Multi-task Fine-tuning, and Video-centric Fine-tuning. The first three stages focus on image understanding, and the final stage enhances video understanding by incorporating temporal information. The Vision Encoder Adaptation Stage focuses on fine-tuning the vision encoder, initialized with SigLIP, on a large-scale image dataset, allowing it to process images at varying resolutions. The Vision-Language Alignment Stage introduces multimodal knowledge, making the LLM and the vision encoder trainable to integrate vision and language understanding. In the Multi-task Fine-tuning Stage, instruction fine-tuning is performed using multimodal question-answering data, including image and video questions, improving the model’s ability to follow natural language instructions and process temporal information. The Video-centric Fine-tuning Stage unfreezes all parameters to enhance the model’s video understanding capabilities. The training data comes from diverse sources like scene images, documents, charts, fine-grained images, and video data, ensuring comprehensive multimodal understanding.
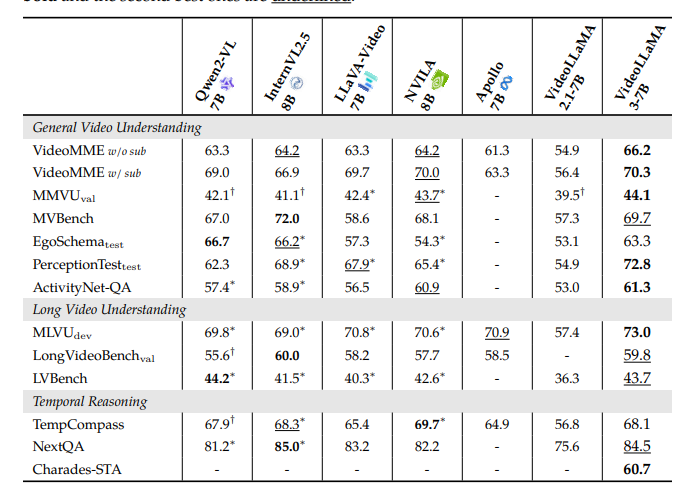
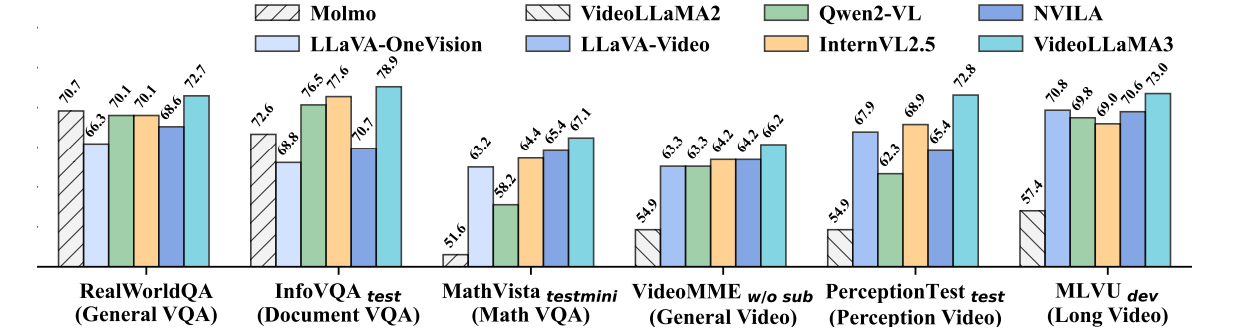
Researchers conducted experiments to evaluate the performance of VideoLLaMA3 across image and video tasks. For image-based tasks, the model was tested on document understanding, mathematical reasoning, and multi-image understanding, where it outperformed previous models, showing improvements in chart understanding and real-world knowledge question answering (QA). In video-based tasks, VideoLLaMA3 performed strongly in benchmarks like VideoMME and MVBench, proving proficient in general video understanding, long-form video comprehension, and temporal reasoning. The 2B and 7B models performed very competitively, with the 7B model leading in most video tasks, which underlines the model’s effectiveness in multimodal tasks. Other areas where important improvements were reported were OCR, mathematical reasoning, multi-image understanding, and long-term video comprehension.
At last, the proposed framework advances vision-centric multimodal models, offering a strong framework for understanding images and videos. By utilizing high-quality image-text datasets it addresses video comprehension challenges and temporal dynamics, achieving strong results across benchmarks. However, challenges like video-text dataset quality and real-time processing remain. Future research can enhance video-text datasets, optimize for real-time performance, and integrate additional modalities like audio and speech. This work can serve as a baseline for future advancements in multimodal understanding, improving efficiency, generalization, and integration.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 70k+ ML SubReddit.
🚨 [Recommended Read] Nebius AI Studio expands with vision models, new language models, embeddings and LoRA (Promoted)
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.
Credit: Source link











{kind=link}