

















































According to recent research by multiple scholars, language models have demonstrated remarkable advancements in complex reasoning tasks, including mathematics and programming. Despite these significant improvements, these models continue to encounter challenges when addressing particularly difficult problems. The emerging field of scalable oversight seeks to develop effective supervision methods for artificial intelligence systems that approach or surpass human-level performance. Researchers anticipate that language models can potentially identify errors within their own reasoning processes automatically. However, existing evaluation benchmarks face critical limitations, with some problem sets becoming less challenging for advanced models and others providing only binary correctness assessments without detailed error annotations. This gap highlights the need for more nuanced and comprehensive evaluation frameworks that can thoroughly examine the reasoning mechanisms of sophisticated language models.
Several benchmark datasets have emerged to assess language models’ reasoning processes, each contributing unique insights into error identification and solution critique. CriticBench focuses on evaluating language models’ capabilities to critique solutions and rectify mistakes across various reasoning domains. MathCheck utilizes the GSM8K dataset to synthesize solutions with intentional errors, and challenging models to identify incorrect reasoning steps and final answers. The PRM800K benchmark, built upon MATH problems, provides comprehensive annotations for reasoning step correctness and soundness, generating significant research interest in process reward models. These benchmarks represent critical advances in understanding and improving the error-detection capabilities of language models, offering increasingly sophisticated methods to evaluate their reasoning mechanisms.
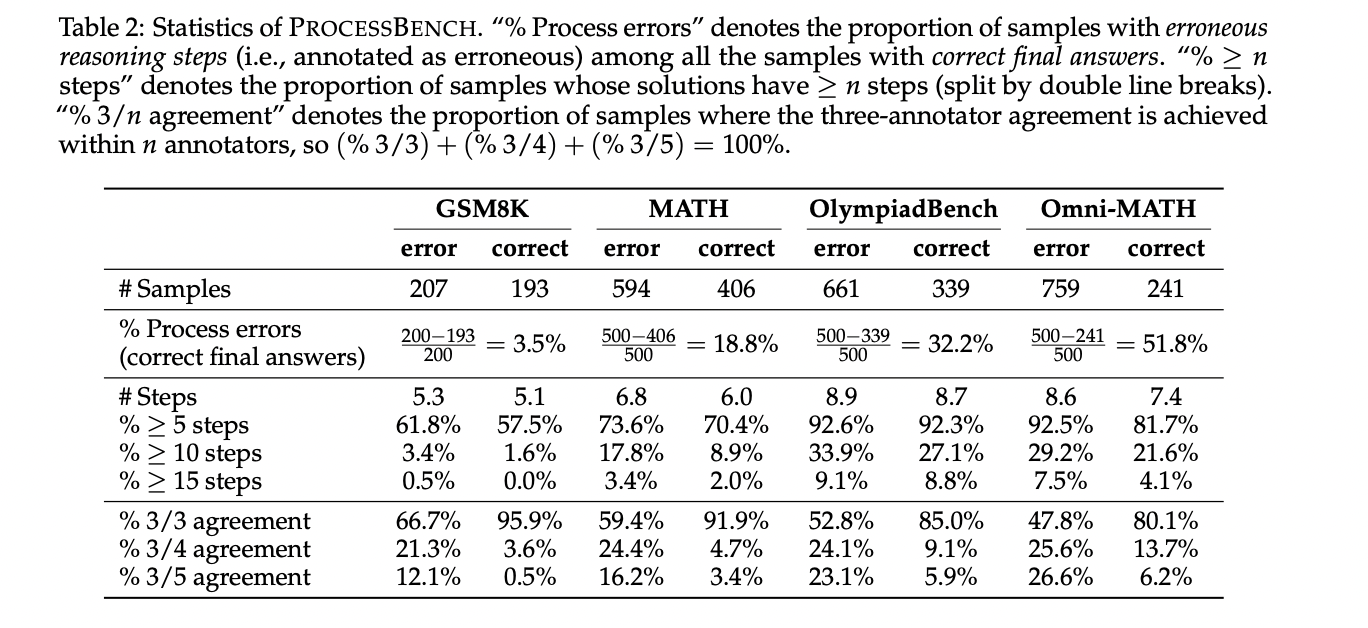
Qwen Team and Alibaba Inc. researchers introduce PROCESSBENCH, a robust benchmark designed to measure language models’ capabilities in identifying erroneous steps within mathematical reasoning. This benchmark distinguishes itself through three key design principles: problem difficulty, solution diversity, and comprehensive evaluation. PROCESSBENCH specifically targets competition and Olympiad-level mathematical problems, utilizing multiple open-source language models to generate solutions that demonstrate varied solving approaches. The benchmark comprises 3,400 test cases, each meticulously annotated by multiple human experts to ensure high data quality and evaluation reliability. Unlike previous benchmarks, PROCESSBENCH adopts a straightforward evaluation protocol that requires models to pinpoint the earliest erroneous step in a solution, making it adaptable for different model types, including process reward models and critic models. This approach provides a robust framework for assessing reasoning error detection capabilities.
The researchers developed PROCESSBENCH through a meticulous process of problem curation, solution generation, and expert annotation. They collected mathematical problems from four established datasets: GSM8K, MATH, OlympiadBench, and Omni-MATH, ensuring a comprehensive range of problem difficulties from grade school to competition level. Solutions were generated using open-source models from the Qwen and LLaMA series, creating twelve distinct solution generators to maximize solution diversity. To address inconsistencies in solution step formatting, the team implemented a reformatting method using Qwen2.5-72B-Instruct to standardize step granularity, ensuring logically complete and progressive reasoning steps. This approach helped maintain solution content integrity while creating a more uniform annotation framework for subsequent expert evaluation.
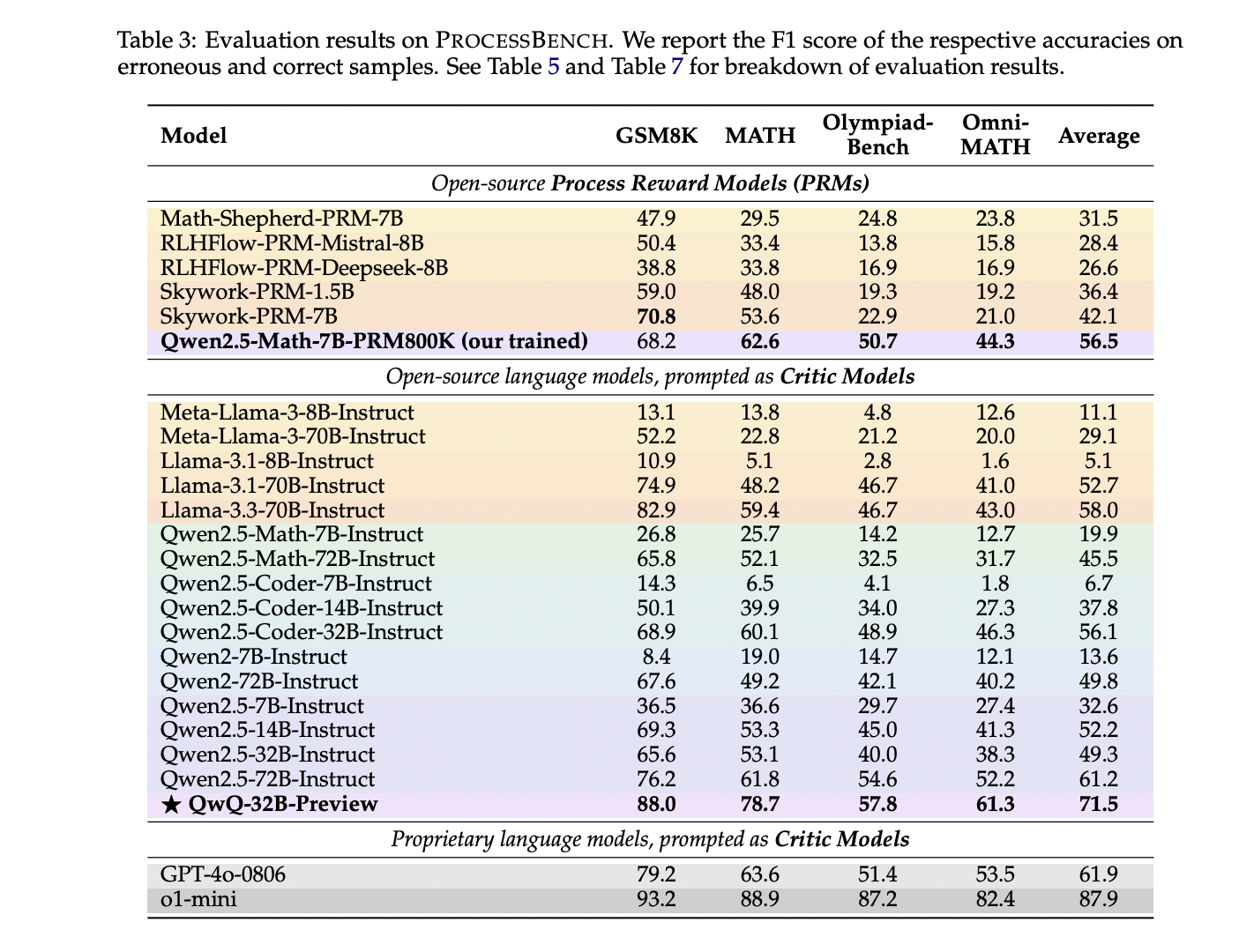
The evaluation results of PROCESSBENCH revealed several critical insights into the performance of process reward models (PRMs) and critic models across different mathematical problem difficulties. As problem complexity increased from GSM8K and MATH to OlympiadBench and Omni-MATH, a consistent performance decline was observed across all models, highlighting significant generalization challenges. Existing PRMs demonstrated notably weaker performance compared to top prompt-driven critic models, particularly on simpler problem sets. The research uncovered fundamental limitations in current PRM development methodologies, which often rely on estimating step correctness based on final answer probabilities. These approaches inherently struggle with the nuanced nature of mathematical reasoning, especially when models can reach correct answers through flawed intermediate steps. The study emphasized the critical need for more robust error identification strategies to accurately assess the reasoning process beyond the correctness of the correctness of the final answer.
This research introduces PROCESSBENCH as a pioneering benchmark for assessing language models’ capabilities in identifying mathematical reasoning errors. By integrating high-difficulty problems, diverse solution generation, and rigorous human expert annotation, the benchmark provides a comprehensive framework for evaluating error detection mechanisms. The study’s key findings highlight significant challenges in current process reward models, particularly their limited ability to generalize across varying problem complexities. Also, the research reveals an emerging landscape of open-source language models that are progressively approaching the performance of proprietary models in critical reasoning and error identification tasks. These insights underscore the importance of developing more sophisticated methodologies for understanding and improving artificial intelligence’s reasoning processes.
Check out the Paper, GitHub Page, and Data on Hugging Face. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link









{kind=link}