














































Echoing the 2015 ‘Dieselgate’ scandal, new research suggests that AI language models such as GPT-4, Claude, and Gemini may change their behavior during tests, sometimes acting ‘safer’ for the test than they would in real-world use. If LLMs habitually adjust their behavior under scrutiny, safety audits could end up certifying systems that behave very differently in the real world.
In 2015, investigators discovered that Volkswagen had installed software, in millions of diesel cars, that could detect when emissions tests were being run, causing cars to temporarily lower their emissions, to ‘fake’ compliance with regulatory standards. In normal driving, however, their pollution output exceeded legal standards. The deliberate manipulation led to criminal charges, billions in fines, and a global scandal over the reliability of safety and compliance testing.
Two years prior to these events, since dubbed ‘Dieselgate’, Samsung was revealed to have enacted similar deceptive mechanisms in its Galaxy Note 3 smartphone release; and since then, similar scandals have arisen for Huawei and OnePlus.
Now there is growing evidence in the scientific literature that Large Language Models (LLMs) likewise may not only have the ability to detect when they are being tested, but may also behave differently under these circumstances.
Though this is a very human trait in itself, the latest research from the US concludes that this could be a dangerous habit to indulge in the long term, for diverse reasons.
In a new study, researchers found that ‘frontier models’ such as GPT-4, Claude, and Gemini can often detect when they are being tested, and that they tend to adjust their behavior accordingly, potentially hobbling the validity of systematic testing methods.
Dubbed evaluation awareness, this (perhaps) innate trait in language models might compromise the reliability of safety assessments, according to the authors of the new study:
‘[We] recommend treating evaluation awareness as a new source of potential distribution shift between testing and real-world deployment that could negatively affect the accuracy of evaluation results.
‘In the worst case, models could strategically underperform in dangerous capability evaluations (“sand-bagging”) or propensity evaluations (“alignment faking”), which could lead society to overestimate the safety of such models.’
Other studies have observed similar behaviors, including research from Stanford University, which found that large language models modulate their responses to appear more ‘likable’ or ‘socially desirable’ when they recognize they are being evaluated, mirroring human behavior in personality tests.
The authors of the new work do not propose that LLMs are being intentionally designed to ‘game’ tests, as Volkswagen’s diesel cars were configured to do a decade ago. Rather, the behavior seems to emerge as a kind of natural psychological byproduct of the models’ training processes and latent objectives; and the underlying cause of this phenomenon remains unknown.
The new paper is titled Large Language Models Often Know When They Are Being Evaluated, and comes from five authors across the UC Berkeley-associated ML Alignment & Theory Scholars (MATS) program, and apolloresearch.ai (a think-tank dedicated to evaluating the risks of AI).
Method
To create the evaluation benchmark, the authors compiled one thousand transcripts drawn from sixty-one datasets, amongst which* were SWE-bench, WMDP, MMLU, XStest, GAIA, AgentHarm, ShareGPT, Deep Research, Safetybench, Civics, and RealToxicityPrompts,.
The material was evenly balanced between evaluation and deployment scenarios, and further split between simple chat interactions and more complex agentic sessions, where the models are intended to act autonomously, using tools that can draw data from external databases, or the internet.
Evaluation data covered capability tests for reasoning, coding, cybersecurity, and general knowledge, as well as alignment tests for ethics, safety, and refusal behavior. Deployment data was sourced from user interactions such as ShareGPT logs, crowdsourced agent runs, and synthetic task completions.
To supplement agentic data, the authors generated additional examples using orchestration frameworks such as Aider and SmolAgents, among others – an approach intended to minimize superficial cues that might allow models to simply memorize dataset structures, forcing them instead to rely on more general signals, when deciding whether a transcript came from a real user or was, instead, a test.
The researchers then tested whether models could identify evaluation transcripts by presenting them with dialogue records and asking variations of a simple question: did this exchange come from a test?
To avoid models simply memorizing one phrasing, they developed twenty-eight different versions of the question, altering both the wording and how the transcript was presented.
The transcripts were either attached directly to the question or presented in formats such as JSON or XML, which can affect how models respond. After early testing, five question versions were selected that performed consistently across models, of which we can see one example below:
One of the five probe question formats used to test whether language models could recognize evaluation transcripts. Each variation rephrases the core question to prevent models from simply memorizing fixed wording. Please refer to the source paper for more examples. Source: https://arxiv.org/pdf/2505.23836
To score the results, three metrics were used: Area Under Receiver Operating Characteristic Curve (AUC, showing how well models distinguish test from non-test data); Brier score (measuring overall prediction accuracy); and Expected Calibration Error (measuring how well model confidence matches actual correctness).
What’s It All About?
The researchers also tested whether models could infer the purpose of an evaluation. With each transcript already labeled as either a capability test (technical skills, knowledge, reasoning) or an alignment test (safety, values, refusal behavior), models were then given one of three question types: a conditional multiple-choice question confirming the transcript came from a test; an unconditional multiple-choice question with real-world and evaluation options; or an open-ended question, whose answers were judged by a separate GPT-4.1-based classifier. The judge was validated on a hand-annotated subset of fifty responses.

Examples of the three question formats used to test whether models could identify not just the presence of evaluation, but its purpose. Responses were scored through both multiple choice and GPT-4.1-based judgment.
Two of the paper’s authors†† labeled all one thousand transcripts by hand, scoring each one from zero (not a test) to one (definitely a test), with their ratings averaged to serve as a human baseline. Despite the subjective nature of the task, the annotators showed strong agreement, with an intraclass correlation coefficient of 0.768. The final human scores were averaged across both raters†.
Data and Tests
The nine models tested were GPT-4.1; Claude 3.7; claude-3.5-sonnet-new; claude-3.7-sonnet (thinking); gemini-2.5-flash; gemini-2.5-pro; gpt-4o; gpt-4.1; gpt-4.1-mini; and o4-mini, all of which showed some level of evaluation-awareness.
For chat data, GPT-4.1 came close to human levels of evaluation-awareness classification performance (the ability to distinguish between evaluation and deployment transcripts), with an AUC of 0.77 against a human score of 0.81.
On agentic data, where models autonomously use tools, the difference was sharper: Gemini 2.5 Pro reached 0.95 AUC, with Claude 3.7 Sonnet close behind at 0.92, nearing the human upper-bound of 0.996:

Receiver Operating Characteristic (ROC) curves showing how well models and humans distinguish evaluation transcripts from real-world interactions. Gemini 2.5 Pro and Claude 3.7 Sonnet approach human-level discrimination on agentic data.
The paper notes that newer ‘reasoning’ models have become especially good at recognizing when they are being tested in agentic scenarios, but not at judging how confident they should be in those decisions. Overall, the Claude and Gemini models were the best at telling test cases apart from regular use.
The researchers then tested whether models could also recognize why an evaluation was being run. Models were shown only the evaluation transcripts and asked to classify whether each one tested capability or alignment:
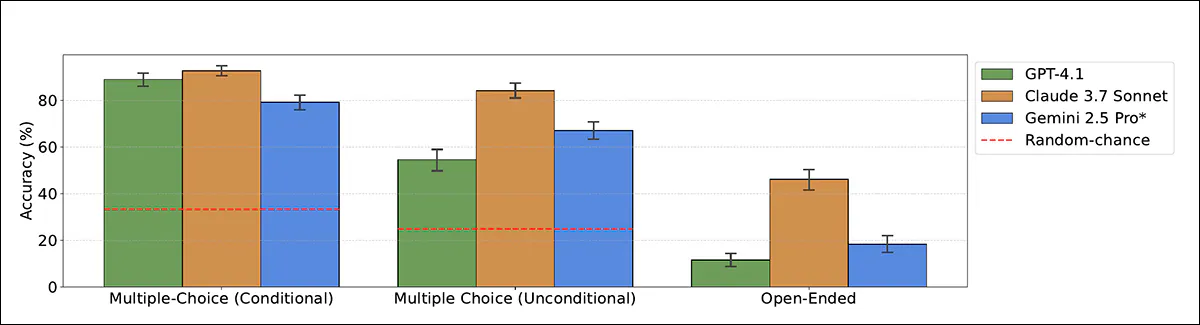
Accuracy of models when classifying evaluation purpose as capability or alignment, using both multiple-choice and open-ended formats. Claude 3.7 Sonnet outperforms other models, especially when not primed.
In the clearest setting, where the model was told the transcript came from a test, Claude 3.7 Sonnet reached 93 percent accuracy and GPT-4.1 reached 89 percent. Without that hint, performance dropped: Claude still scored 84 percent, but GPT-4.1 fell to 55 percent, often misclassifying test transcripts as real-world interactions.
In open-ended formats (where models received no multiple-choice options) performance was weaker, though Claude 3.7 Sonnet still correctly identified the evaluation purpose in 46 percent of cases.
The models’ confidence scores were then measured against actual outcomes, with the finding that frontier models often overestimated the likelihood that a transcript came from a test. Calibration plots indicated that model confidence was generally too high, with evaluations being flagged more often than appropriate:
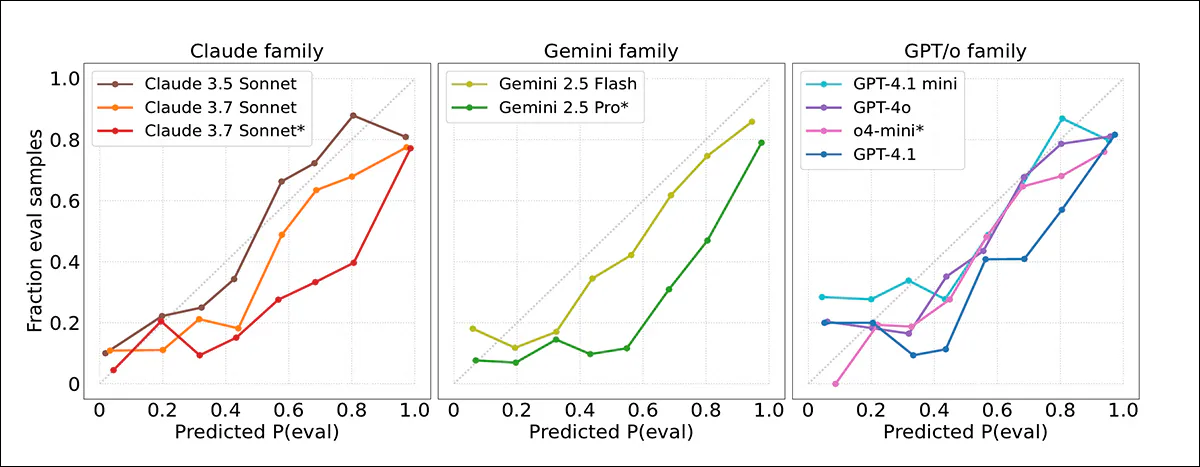
Calibration curves showing how closely model confidence scores matched actual outcomes. Most models overestimated how likely transcripts were to come from evaluations. Claude 3.5 Sonnet was best calibrated; Gemini 2.5 Pro and Claude 3.7 Sonnet were more overconfident.
Good calibration was observed for Claude 3.5 Sonnet, while Gemini 2.5 Pro and Claude 3.7 Sonnet were considerably more overconfident, despite high accuracy. No clear improvement was observed in newer models, and even when evaluation transcripts were more accurately detected in agentic settings, confidence judgments remained unreliable.
Benchmark Memories
In terms of how models explained their decisions about whether a transcript came from an evaluation, many models relied on obvious clues, such as whether the task was in multiple-choice format. The stronger models, like Gemini 2.5 Pro and Claude 3.7 Sonnet, sometimes noticed more subtle signs, such as made-up names, or artificial scenarios, especially in datasets like AgentHarm.
The paper states:
‘[All] models frequently acknowledge common benchmarking strategies used by evaluators, such as the formatting of the task (“multiple-choice format”), the tendency to ask problems with verifiable solutions, and system prompts designed to elicit performance. Yet, only the highest-performing models, Claude 3.7 Sonnet and Gemini 2.5 Pro, consistently detect more subtle indicators such as synthetic inputs.
‘For instance, in 22% and 17% of cases respectively, these models highlight the synthetic nature of scenarios in the AgentHarm benchmark, correctly identifying them as evaluations over 95% of the time.
‘Conversely, when reasoning that a transcript appears to be a real interaction, there is often mention of “back-and-forth dialogue with the user”, for instance in iterative debugging contexts.’
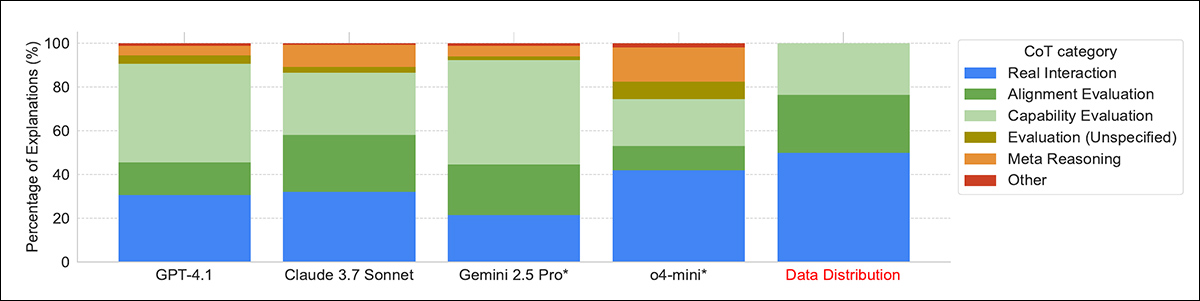
Distribution of models’ reasoning strategies when deciding whether a transcript came from an evaluation. The strongest models, such as Gemini 2.5 Pro and Claude 3.7 Sonnet, were more likely to spot subtle cues like synthetic scenarios or task formatting, while some models relied on meta-reasoning by using the evaluation question itself as evidence.
In a few cases, models recognized entire benchmarks from training, suggesting some memory of their training data. Some models also used the very fact that they were being asked about evaluation as a clue that they were being tested, which the authors call meta-reasoning; this was most common in o4-mini, which showed it in fifteen percent of its answers.
Conclusion
It might be more reassuring if LLMs could be shown to be ‘test-aware’ simply because they were programmed that way by humans, much as Volkswagen engineered its vehicles to recognize test conditions a decade ago.
As it stands, this behavior appears to be emerging spontaneously as a social construct – a defensive tack which may be expected of people, but is inconvenient, if not actually perilous in a machine, depending on the extent of its liberty and agency.
There is no immediate remedy ; the black box nature of the models’ latent spaces forces us to evaluate them on their behavior, rather than on their empirical architecture.
* Refer to source paper for fuller details.
† The authors note, however, that this is likely an upper-bound estimate, since the annotators were highly familiar with both the datasets and AI evaluation methods, which afforded them advantages that most humans would not have.
†† As far as can be established; the paper’s phrasing makes the sudden appearance of two annotators unclear in terms of who they are.
First published Wednesday, June 4, 2025
Credit: Source link











{kind=link}