
















Large language models become static after pretraining. Their knowledge does not update as the world changes. Retraining a full LLM is too expensive at modern scales. Fine-tuning risks degrading previously learned knowledge. Retrieval-augmented generation (RAG) struggles when answers require reasoning across many documents.
A team of researchers from the National University of Singapore, MIT CSAIL, A*STAR, and the Singapore-MIT Alliance for Research and Technology (SMART) proposes a new approach called MEMO (Memory as a Model).
What Problem Does MEMO Solve?
Existing methods for integrating new knowledge into LLMs fall into three categories. Non-parametric methods like RAG retrieve documents at inference time. They are sensitive to retrieval noise and struggle with cross-document reasoning. Parametric methods such as continual pretraining or supervised fine-tuning internalize knowledge into model weights. They are computationally expensive and cause catastrophic forgetting, where new training degrades previously acquired knowledge. Latent memory methods compress knowledge into soft tokens. These representations are tightly bound to the model that produced them — a limitation the research team calls representation coupling which limits transferability across LLMs.
MEMORY as a Separate Model
MEMO separates memory from reasoning. The MEMORY model is a small, dedicated language model trained to internalize knowledge from a target corpus. The EXECUTIVE model is the main LLM — frozen and queried only through its standard input-output interface.
In experiments, the MEMORY model is Qwen2.5-14B-Instruct. The EXECUTIVE model is either Qwen2.5-32B-Instruct or Gemini-3-Flash, a proprietary closed-source model. Because MEMO treats the EXECUTIVE model as a black box, it does not require weight access or output logits.
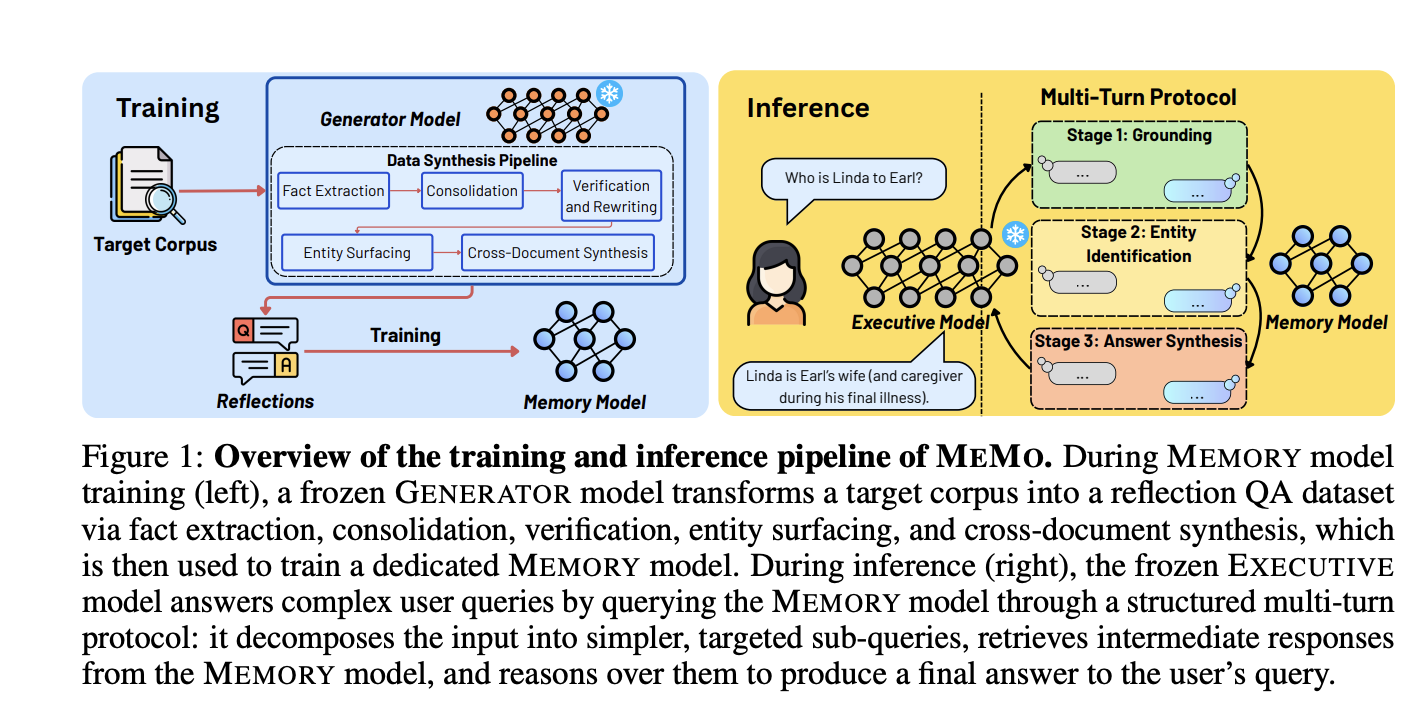
How the MEMORY Model is Trained
Training begins with a five-step data synthesis pipeline guided by a GENERATOR model — Qwen2.5-32B-Instruct in experiments. The pipeline converts a raw document corpus into a reflection QA dataset: question-answer pairs that represent corpus knowledge under diverse query variations.
The five steps are:
- Fact extraction — direct extraction of explicitly stated facts, and indirect extraction of inferred information, run in parallel per document chunk.
- Consolidation — QA pairs sharing a common context (entity, time period, relationship) are merged into multi-fact pairs.
- Verification and rewriting — each QA pair is checked for self-containment. Pairs with unresolved pronouns or implicit references are rewritten using the source chunk or discarded.
- Entity surfacing — QA pairs are generated where questions encode entity attributes and relationships, and answers reveal entity identities. This targets the reversal curse, where models trained on “A is B” fail to infer “B is A.”
- Cross-document synthesis — the GENERATOR model constructs QA pairs spanning multiple documents. It identifies two types of cross-document connections: converging clues (multiple documents about the same entity) and parallel properties (different entities sharing a common attribute or role).
Step-5 is the most critical component. A leave-one-out ablation shows that removing it drops accuracy from 24.00% to 6.37% on NarrativeQA. It is also the dominant source of training pairs in the final dataset.
The MEMORY model is then trained via supervised fine-tuning (SFT). The loss is computed over answer tokens only. Source documents are never provided at inference. The model must answer from internalized parametric knowledge.
Inference: The Structured Multi-Turn Protocol
At inference, the EXECUTIVE model queries the MEMORY model through a structured multi-turn protocol with three sequential stages.
Stage 1: Grounding. The EXECUTIVE model decomposes the query into atomic sub-questions. Each targets a single identifying constraint. The MEMORY model answers each independently.
Stage 2: Entity identification. Using the grounding responses, the EXECUTIVE model issues targeted follow-up sub-queries. It iteratively narrows down candidate entities until one is confirmed or the stage budget runs out.
Stage 3: Answer seeking and synthesis. Conditioned on the identified entity, the EXECUTIVE model queries the MEMORY model for supporting facts. It then synthesizes all retrieved responses into a final answer.
The MEMORY model’s responses are compact natural-language snippets. Their length is independent of corpus size, so retrieval cost does not scale with the number of documents. This contrasts with RAG, where inference cost grows with the corpus.
Experimental Results
MEMO is evaluated on three benchmarks: BrowseComp-Plus (multi-hop deep-research), NarrativeQA (discourse understanding over books and movie scripts), and MuSiQue (2–4 hop reasoning over Wikipedia paragraphs). Baselines include BM25, NV-Embed-V2, HippoRAG2, and Cartridges. Cartridges requires white-box access to the EXECUTIVE model and scored 0.00% on BrowseComp-Plus and 3.75% on NarrativeQA.
On NarrativeQA with Gemini-3-Flash, MEMO achieves 53.58%. HippoRAG2 reaches 23.21% on the same setup. On MuSiQue, MEMO achieves 60.20% against HippoRAG2’s 57.00%. On BrowseComp-Plus, MEMO achieves 66.67% against HippoRAG2’s 66.33%.
With Qwen2.5-32B-Instruct as EXECUTIVE model, MEMO achieves 54.22% on BrowseComp-Plus and 48.30% on MuSiQue. Switching to Gemini-3-Flash yields gains of 12.45%, 26.73%, and 11.90% on the three benchmarks. The MEMORY model is not retrained when the EXECUTIVE model changes.
Robustness to retrieval noise: The research team evaluates performance when distractor documents are added to the corpus. NV-Embed-V2 and HippoRAG2 drop by up to 6.22% on BrowseComp-Plus when one negative document is added per evidence document. MEMO’s accuracy on the same benchmark changes by +0.55% — within one standard deviation.
MEMORY model architecture robustness: The research team also tests three MEMORY model families at similar parameter scale: Qwen2.5-1.5B-Instruct, Gemma3-1B-IT, and LFM2.5-1.2B-Instruct (a hybrid state-space and transformer architecture). Performance is largely consistent across all three, indicating the framework is not sensitive to the specific pretraining lineage of MEMORY model.
Continual Knowledge Integration via Model Merging
MEMO supports incremental knowledge updates through model merging. When a new corpus arrives, a separate MEMORY model is trained on it independently. Its task vector — the parameter difference from the base model — is then merged with the existing MEMORY model in parameter space.
The research team test this on NarrativeQA using TIES merging (ρ=0.3). For K=2 corpora, merging accumulates 48 GPU-hours versus 72 GPU-hours for full retraining — a 33% reduction. At K=10, merging scales as Θ(K) while full retraining scales as Θ(K²), yielding a 5.5× saving (240 vs. 1,320 GPU-hours).
The merged MEMORY model trails full retraining by 11.04% under Qwen2.5-32B-Instruct (15.81% vs. 26.85%). It trails by 19.11% under Gemini-3-Flash (34.47% vs. 53.58%). Despite this gap, it outperforms all retrieval baselines on NarrativeQA.
Marktechpost’s Visual Explainer
Key Takeaways
- MEMO trains a dedicated MEMORY model on new knowledge, keeping the main LLM frozen and unchanged.
- A five-step data synthesis pipeline converts raw documents into a reflection QA dataset capturing cross-document relationships.
- At inference, a structured multi-turn protocol decomposes complex queries into targeted sub-queries to the MEMORY model.
- Retrieval cost is fixed at inference time — it does not scale with corpus size, unlike RAG.
- Model merging cuts cumulative training compute by 33% at K=2 corpora and 5.5× at K=10, with a measurable accuracy trade-off.
Check out the Research Paper. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
Credit: Source link











{kind=link}