
















Stability AI has released open weights for Stable Audio 3 along with a technical research paper. Stable Audio 3 is a family of latent diffusion models that generate stereo audio at 44.1 kHz. The models support variable-length outputs, inpainting-based editing, and fast inference.
What Is Stable Audio 3?
Stable Audio 3 is a family of three model scales: small, medium, and large. A latent diffusion model generates audio by learning to progressively remove noise from a compressed representation of audio, called a latent. The model learns a mapping from noise to data by training on many (noisy latent, audio) pairs.
The three model scales differ in capacity and maximum generation length. All parameter counts below are for the diffusion transformer component only. Each model also includes a SAME autoencoder (108M parameters for SAME-S, 852M for SAME-L).
- small-music — 459M diffusion transformer parameters, up to 2 minutes, music only.
- small-sfx — 459M diffusion transformer parameters, up to 2 minutes, sound effects only.
- medium — 1.4B diffusion transformer parameters, up to 6 minutes and 20 seconds, music and sound effects.
- large — 2.7B diffusion transformer parameters, up to 6 minutes and 20 seconds, music and sound effects.
Open weights for small and medium are available on Hugging Face. Large is available under an enterprise license.
Architecture: Two Components
Stable Audio 3 has two main components: a semantic-acoustic autoencoder called SAME, and a diffusion transformer that generates latent sequences conditioned on text, duration, and inpainting masks.
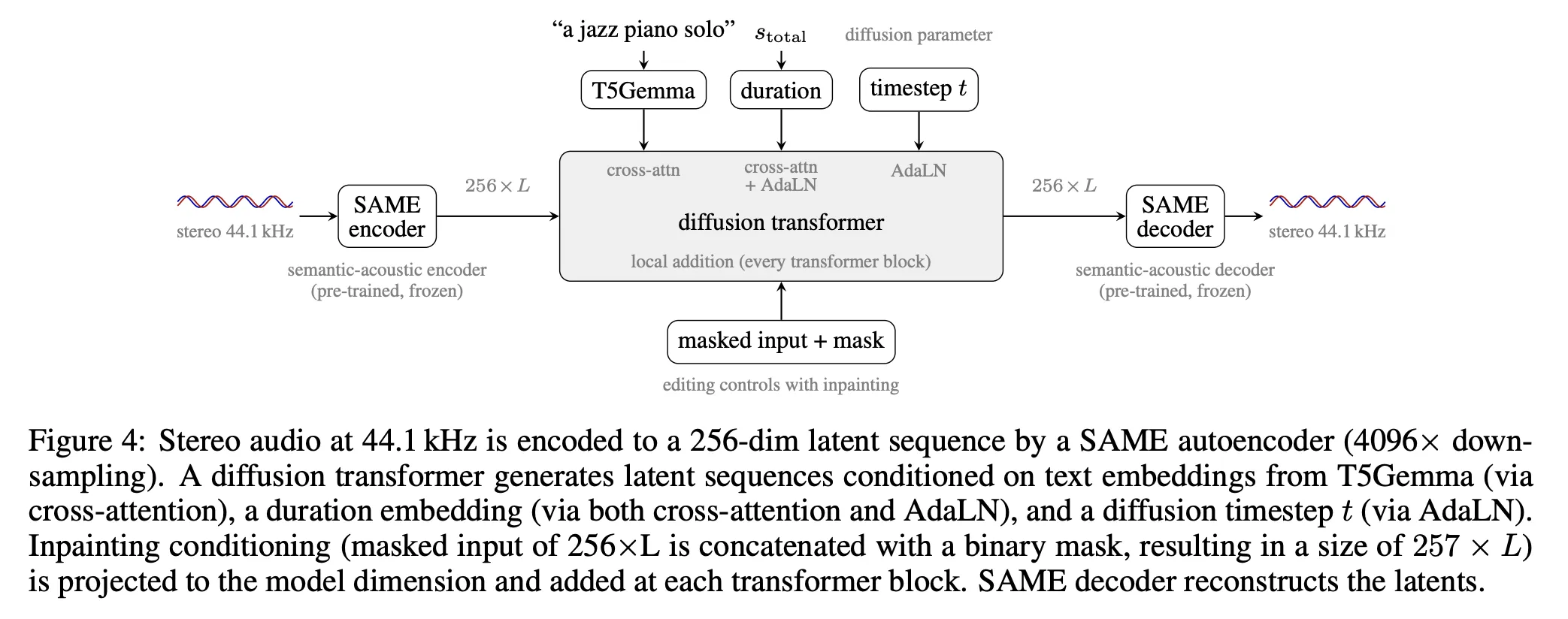
The SAME Autoencoder
SAME (Semantically-Aligned Music autoEncoder) converts stereo 44.1 kHz audio into a compact latent representation and back. Its key design parameter is a 4096× downsampling ratio — substantially higher than the 1024× to 2048× ratios common in prior audio autoencoders. This higher ratio reduces latent sequence lengths enough for long-form generation to run on consumer hardware.
SAME achieves its 4096× compression through two stages. First, a patching stage reshapes stereo audio into non-overlapping patches of 256 samples per channel, achieving 256× downsampling. Second, a Transformer Resampling Block (TRB) applies a further 16× downsampling using learnable output embeddings interleaved with the input sequence, processed through a transformer. The combined output is a 256-dimensional latent sequence at approximately 10.76 Hz for a 44.1 kHz input.
The SAME autoencoder is trained with five loss types: spectral reconstruction, adversarial, diffusion alignment, semantic regression (predicting chroma and interaural level difference), and contrastive latent alignment. These losses push the latent to preserve both acoustic reconstruction quality and semantic structure. A soft-normalisation bottleneck constrains the scale of the latent, providing deterministic encoding.
The SAME autoencoder is frozen during diffusion training. Small models use SAME-S (108M parameters, optimized for CPU inference); medium and large use SAME-L (852M parameters).
The Diffusion Transformer
The diffusion transformer operates on SAME latents. Conditioning enters through three pathways:
- Text — a frozen T5Gemma encoder produces a sequence of 256 embeddings of dimension 768. Short prompts are padded to 256 with a learned embedding; long prompts are truncated.
- Duration — encoded as a Fourier features vector and injected via both Adaptive Layer Normalization (AdaLN) and cross-attention alongside the text prompt.
- Inpainting — a binary mask concatenated with the masked reference audio is projected through a 2-layer MLP and added to the residual stream of each transformer block.
Each transformer block contains self-attention, cross-attention, local-additive conditioning for inpainting, and a SwiGLU feed-forward network. Medium and large use differential attention, which computes two separate attention maps using two (Q, K) pairs sharing one set of values V, then subtracts one map from the other. This cancels attention patterns that are common to both heads. The transformer prepends 64 learnable memory embeddings before processing each sequence. These provide a global context buffer that every position can attend to, and are removed before computing any loss.
Variable-Length Generation
Most prior latent diffusion models for audio operate at a fixed maximum sequence length. Generating a short clip still requires running inference at full length, wasting compute on silence. Stable Audio 3 is trained to generate audio at variable lengths natively, using three mechanisms:
- Variable-length flash attention and masked loss — sequences shorter than the batch maximum are right-padded in latent space. Padding positions are excluded from self-attention and from the loss.
- Per-element timestep shifts — longer sequences retain more structure at a given noise level due to redundancy between neighboring elements. To compensate, the noise schedule is shifted toward higher noise levels for longer sequences during training, using a logistic shift parameterized by µ (interpolating between µmin=0.5 and µmax=1.15 based on sequence length).
- Silence augmentation — the signal region is randomly extended with pre-computed silence embeddings drawn from an exponential distribution, averaging 4 seconds. This teaches the model to terminate audio with natural silence.
The practical result is that inference cost scales with output duration. Medium generates 20 seconds of audio in approximately 0.62 seconds on an H200. Generating 380 seconds takes 1.31 seconds on the same hardware.
Three-Stage Training Pipeline
Stage 1 — Flow Matching Pre-Training. The model learns a velocity field that transports Gaussian noise toward audio latents. Training uses minibatch optimal transport coupling via Sinkhorn iterations, which pairs each data sample with the closest available noise vector in the batch. This straightens training trajectories and reduces crossing transport paths. Inpainting is trained jointly throughout: at each step, one of three mask types is sampled — full mask (80%, equivalent to unconditional generation), random segment masks (10%), or a causal prefix mask for continuation (10%).
Stage 2 — Distillation Warmup. A frozen copy of the flow matching model (teacher) generates 15-step DPM++ trajectories with CFG scale 5. The student is trained for 10,000 steps to map any intermediate noisy state directly to the teacher’s final denoised output in one step, using an MSE loss. This collapses the multi-step ODE into a single-step denoiser. The trade-off is that MSE regression produces outputs that regress toward the conditional mean, reducing fine-grained detail.
Stage 3 — Adversarial Post-Training. This stage replaces the MSE objective with a relativistic adversarial setup. A discriminator (initialized from the base flow matching model) evaluates the student’s one-step denoised outputs directly against real data. The teacher is discarded entirely at this stage. The generator is trained with two losses: a relativistic adversarial loss (L_R) and a CLAP alignment loss (L_CLAP). The discriminator is trained with L_R and a contrastive loss (L_C) that penalizes the discriminator for ignoring text-audio alignment (it is trained to distinguish correctly paired audio-text pairs from shuffled ones). The adversarial setup allows the model to recover the perceptual sharpness that MSE distillation removes.
Inference: Ping-Pong Sampling and No CFG
The post-trained model can generate audio in a single forward pass. However, single-step generation from pure noise remains difficult. Stable Audio 3 uses ping-pong sampling at inference: the model denoises to a clean estimate, then adds new noise at a reduced level, then denoises again. This repeats for 8 steps using a logSNR-uniform schedule (N+1 equally-spaced steps in the interval [λmin, λmax] = [−6.2, 2.0]). The iterative denoise-then-renoise schedule allows each step to correct errors from the previous step.
Stable Audio 3 does not require classifier-free guidance (CFG) at inference. Standard diffusion models run two forward passes per step — one conditional, one unconditional — and interpolate. Here, CFG quality gains are internalized during distillation warmup, where the student is trained to match CFG-enhanced teacher trajectories. Text-audio alignment is further reinforced through L_CLAP during adversarial post-training. This eliminates the two-pass-per-step cost of CFG.
Prompt formatting note: All Stable Audio 3 models trained on AudioSparx (small-music, medium, large) require prompt prefixes to function correctly. Music prompts should be prepended with "TrackType: Music, VocalType: Instrumental," and sound effects prompts with "TrackType: SFX,".
Evaluation Results
Instrumental music (Song Describer Dataset, 120s). On FAD (lower is better) and CLAP score (higher is better), large achieves FAD 0.101 / CLAP 0.393. Medium achieves FAD 0.107 / CLAP 0.390. Stable Audio 2.5 (the internal prior-generation baseline) achieves FAD 0.106 / CLAP 0.395. In the listening test, medium and large score higher on musicality (MUS) than Stable Audio 2.5 (4.15 and 4.30 vs. 3.70 out of 5, respectively). Inference time for 120s audio on an H200: 0.45s for small, 0.78s for medium, 0.81s for large. Stable Audio 2.5 takes 0.85s for the same length.
Sound effects (BBC Sound Effects Dataset, 5s). Medium achieves FAD 0.369 / CLAP 0.369. The next-best open-weight baselines are Stable Audio Open Small (FAD 0.500 / CLAP 0.277) and Stable Audio Open (FAD 0.501 / CLAP 0.263). Woosh Flow scores FAD 0.580.
Audio editing (inpainting). The research team evaluates three inpainting settings: single region, two independent regions, and continuation. For music, medium achieves FAD-full of 0.046 on single inpainting and 0.046 on double inpainting. Large achieves 0.047 on both. For continuation, medium achieves FAD-full 0.074 and large achieves 0.071. Sound effects results follow a similar pattern; continuation shows higher FAD than inpainting in both domains, which the team attributes to the model having less surrounding audio context to anchor the generation.
Comparison
Model specs
Music benchmarks (SDD, 120s)
SFX benchmarks (BBC, 5s)
★ SA3 rows: Parameter counts are for the diffusion transformer (DT) component only; SAME autoencoder params are listed separately. Total model size including SAME: small ~567M, medium ~2.25B, large ~3.55B.
Stable Audio 2.5 is an internal Stability AI model not publicly released; included as prior-generation internal baseline from the SA3 paper.
DiffRhythm 2 VAE processes 24kHz input audio and reconstructs at 48kHz (arXiv:2510.22950).
Evaluation setup: Song Describer Dataset (SDD), 120s instrumental music generations, H200 GPU. FAD uses LAION-CLAP embeddings (630k-audioset-best.pt). OVL/REL/MUS are mean opinion scores (1–5) from a 14-participant listening test. Source: SA3 paper Tables 3 and 4. Bold + underline = best score in column.
FAD: Fréchet Audio Distance — lower is better. CLAP: cosine similarity between text and audio embeddings — higher is better.
OVL = overall production quality. REL = text relevance. MUS = musicality (melody/harmony coherence).
ACE-Step 1.5 and DiffRhythm 2 evaluated with instrumental prompts only for fair comparison with SA3 (instrumental-only models). SA3 base flow matching models (50 steps, CFG 7, Euler sampler) are not shown here; see SA3 paper Table 11 for that comparison.
Evaluation setup: BBC Sound Effects Dataset, ≤5s generations matched to reference duration, H200 GPU. FAD uses LAION-CLAP embeddings. OVL/REL from 14-participant listening test. Source: SA3 paper Table 5. Bold + underline = best score in column.
Woosh DFlow achieves the fastest inference (0.06s) but at a quality cost — higher FAD than Woosh Flow. SA3 small-sfx, medium, and large all outperform every competitor on FAD and CLAP at the 5s generation length.
SA3 models do not use classifier-free guidance (CFG) at inference. CFG quality gains are internalized during distillation warmup training.
Key Takeaways
- Stable Audio 3 is a family of open-weight latent diffusion models (small, medium, large) for music and sound effects generation and editing.
- A SAME autoencoder with 4096× downsampling compresses audio into 256-dimensional latents at ~10.76 Hz, making long-form generation tractable on consumer hardware.
- Variable-length generation is natively supported: inference cost scales with requested duration, not a fixed maximum length.
- Three-stage training (flow matching → distillation warmup → adversarial post-training) enables 8-step inference without classifier-free guidance.
- Prompt prefixes (
"TrackType: Music, VocalType: Instrumental,"/"TrackType: SFX,") are required for AudioSparx-trained model variants.
Check out the Paper, Model Weights and Repo here. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
Credit: Source link










{kind=link}