















 That Outperform OpenAI Operator and Gemini 2.5 Computer Use on Online-Mind2Web")

Microsoft Research’s AI Frontiers lab released Fara1.5. It is a family of computer-use agent (CUA) models for the browser. The release ships three sizes: Fara1.5-4B, Fara1.5-9B, and Fara1.5-27B. The models are integrated with MagenticLite, Microsoft’s sandboxed browser interface for these agents.
Computer-use agents are pixel-to-action models that drive a real browser. They read screenshots and emit mouse and keyboard actions to complete tasks. Recent agent products like OpenAI’s Operator and Google’s Gemini 2.5 Computer Use sit in this category.
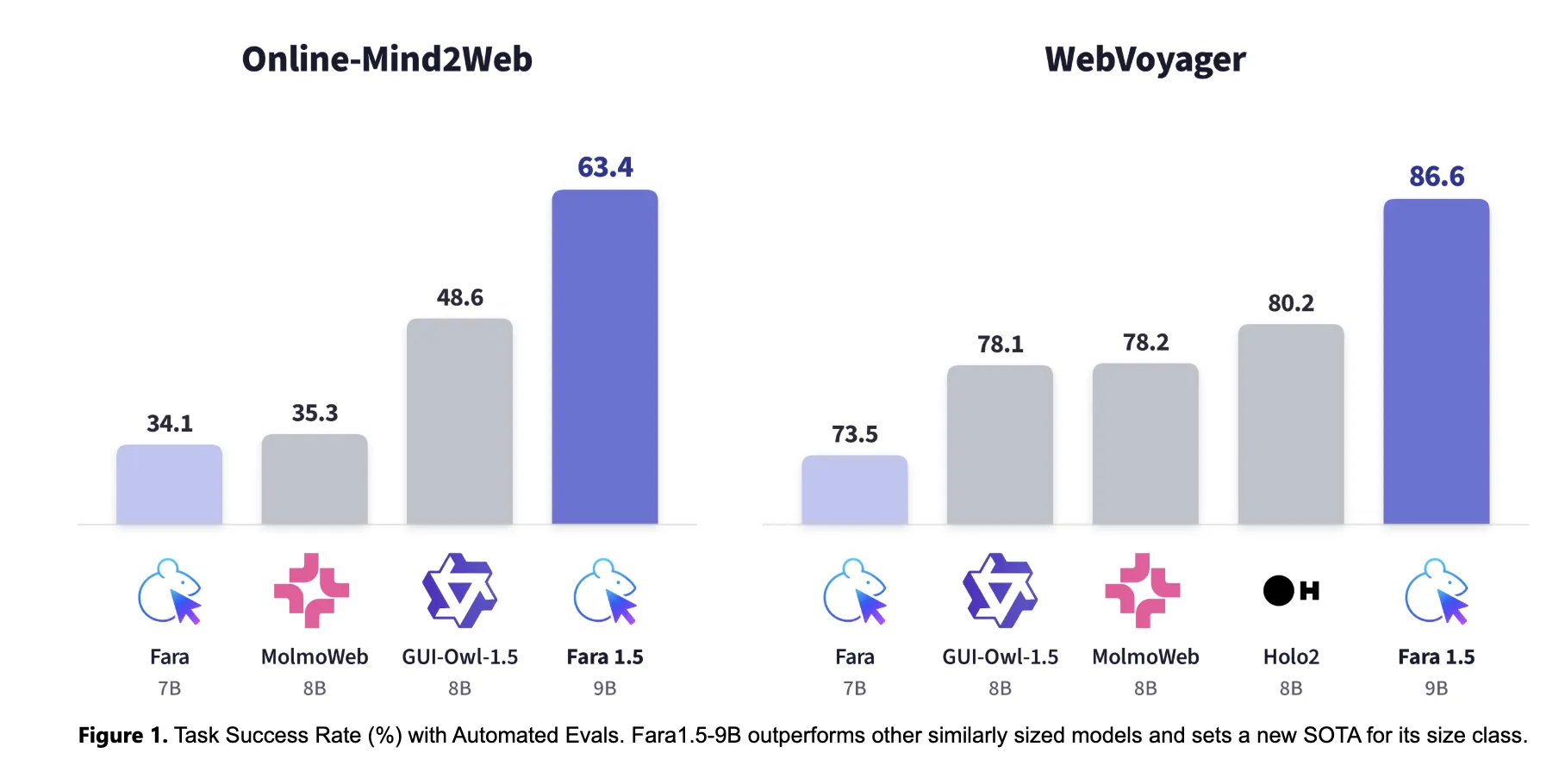
Fara1.5-27B scores 72% task success on Online-Mind2Web. That benchmark covers 300 tasks across 136 popular sites. On the same evaluation, OpenAI’s Operator scores 58.3% and Gemini 2.5 Computer Use scores 57.3%. Yutori’s Navigator n1 reaches 64.7%, and Fara1.5-9B scores 63.4%. That nearly doubles the predecessor Fara-7B, which scored 34.1% on the same benchmark.
Architecture and agent loop
The models use Qwen3.5 base checkpoints in their 4B, 9B, and 27B variants. They operate through an observe-think-act loop. At each step, the model takes the prior conversation history and the three most recent browser screenshots. It then emits thoughts and a single next action.
The action space includes standard mouse and keyboard inputs and web-specific actions like web search. It also exposes meta-actions for context management. These include memorizing facts for later use and asking the user clarification questions. These meta-actions let the agent operate over longer horizons and work collaboratively with users.
Training mix
Training uses supervised fine-tuning on roughly two million samples. The mix is 60% web trajectories and 12.8% synthetic environments. Form filling and user interactions account for 12.5%. Grounding contributes 8.8% and VQA 4.9%. Smaller slices cover GUI drag, instruction following, and safety. Loss is applied only to the three most recent turns in each trajectory.

FaraGen1.5: the synthetic data pipeline
FaraGen1.5 is the synthetic pipeline that produced the training trajectories. It has three modular components: environments, solvers, and verifiers.
Environments split into two types. Open-internet tasks run on live websites that don’t require logins. Gated-domain tasks require authenticated sessions or take irreversible actions, like sending an email.
For gated domains, the team built six synthetic clones called FaraEnvs. They cover Mail, Calendar, Stream, ML, Stay, and Scheduler. Each clone has a realistic frontend, a fully functional API, and a database with persona-based seed data.
These environments were built using GitHub Copilot CLI plus iterative human refinement. Because the team controls the full stack, they know the correct outcome for every task. For tasks that mutate the backend, an LLM judge compares database snapshots before and after execution. Tasks that don’t change state are scored against pre-computed reference answers.
The solver agent uses OpenAI’s GPT-5.4 with custom tools that mirror Fara1.5’s action space. The solver scores 83% on Online-Mind2Web using automated WebJudge. The previous Fara-7B solver scored 67% on the same evaluation. A user simulator is invoked when the solver issues an ask_user call or when it finishes a task.
Three verifiers gate which trajectories enter training. Correctness uses LLM-generated rubrics for open-internet tasks and privileged database judging for synthetic ones. Efficiency penalizes redundant or unnecessary actions. User-interaction verification checks whether the agent paused at critical points.
Critical points and safety
Fara1.5 is trained to stop and ask the user in three situations. First: the task requires personal information the user has not provided. Second: the task description is ambiguous or missing details needed to act. Third: an irreversible action is about to be performed without prior approval.
Safety training uses public safety datasets and internal tasks aligned with Microsoft’s Responsible AI Policy. Inside MagenticLite, all agent actions are logged and auditable. The sandboxed browser also acts as a security boundary between the agent and the user’s machine.
Other benchmarks
On WebVoyager, Fara1.5-27B scores 88.6%, the 9B reaches 86.6%, and the 4B hits 80.8%. The 9B also tops similar-sized peers like MolmoWeb 8B, GUI-Owl-1.5 8B, and Holo2 8B. All Fara1.5 evaluation runs use Browserbase to stabilize sessions and reduce session-level blocking. Numbers are averaged over three independent runs.
On WebTailBench v1.5, which targets long-tail web tasks, Fara1.5-9B scores 64.5% process success and 32.3% outcome success. GPT-5.4 scores 79.6% process and 57.4% outcome on the same benchmark.
Key Takeaways
Here are 5 one-line key takeaways:
- Microsoft Research released Fara1.5, a family of browser computer-use agents in 4B, 9B, and 27B sizes built on Qwen3.5.
- Fara1.5-27B scores 72% on Online-Mind2Web, beating OpenAI Operator (58.3%), Gemini 2.5 CU (57.3%), and Yutori Navigator n1 (64.7%).
- The FaraGen1.5 synthetic data pipeline unlocks training on gated domains via six functional app clones (FaraEnvs) built with GitHub Copilot CLI.
- Fara1.5 pauses to ask the user at critical points: missing info, ambiguous tasks, or irreversible actions without approval.
Check out the Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
Credit: Source link











{kind=link}