














































Research in code embedding models has witnessed a significant breakthrough with the introduction of voyage-code-3, an advanced embedding model specifically designed for code retrieval tasks by researchers from Voyage AI. The model demonstrates remarkable performance, substantially outperforming existing state-of-the-art solutions like OpenAI-v3-large and CodeSage-large. Empirical evaluations across a comprehensive suite of 238 code retrieval datasets reveal that voyage-code-3 achieves an impressive average performance improvement of 13.80% and 16.81% over these competing models, highlighting its potential to revolutionize code search and retrieval technologies.
The development of voyage-code-3 introduces innovative approaches to address the computational challenges in vector-based search, particularly for extensive code repositories. Matryoshka embeddings and advanced quantization techniques emerge as critical strategies to mitigate storage and search costs. The model tackles the linear scalability challenge by supporting lower-dimensional embeddings and implementing binary and int8 quantization methods. These technological advancements enable significant cost reductions while maintaining robust retrieval performance, presenting a transformative solution for large-scale code search and management systems.
The landscape of code retrieval represents a complex domain with multifaceted challenges that extend beyond traditional text search methodologies. Unique computational demands arise from the intricate nature of programming languages, requiring sophisticated algorithmic reasoning and a nuanced understanding of syntax structures. Code retrieval encompasses diverse subtasks, including text-to-code, code-to-code, and docstring-to-code retrievals, each demanding precise semantic comprehension and advanced matching capabilities. These sophisticated retrieval scenarios necessitate advanced embedding models capable of capturing intricate programmatic relationships and context-specific nuances.
The evaluation of voyage-code-3 represents a rigorous and methodical approach to assessing code embedding model performance, addressing critical limitations in existing benchmarking practices. Researchers developed a comprehensive evaluation framework that goes beyond traditional assessment methods, recognizing the inherent challenges in existing datasets. By identifying and mitigating issues such as noisy labels and potential data contamination, the study aimed to create a more robust and realistic assessment of code retrieval capabilities. The evaluation strategy incorporated diverse tasks, including text-to-code and code-to-code retrievals, and utilized repurposed question-answer datasets to provide a more nuanced and comprehensive understanding of the model’s capabilities.

The experimental results of voyage-code-3 demonstrate substantial performance gains across various dimensional configurations and storage cost scenarios. At 1024 and 256 dimensions, the model outperforms OpenAI-v3-large by 14.64% and 17.66%, respectively, showcasing impressive retrieval capabilities. Moreover, the model achieves a 13.80% performance improvement while utilizing only one-third of the original storage costs, comparing 1024 and 3072 dimensions. In an even more remarkable achievement, voyage-code-3 maintains a 4.81% performance advantage at an extraordinary storage cost reduction of 1/384, comparing binary 256-dimensional embeddings with float 3072-dimensional embeddings. The introduction of binary rescoring techniques further enhances retrieval quality, potentially yielding up to a 4.25% improvement when applied to standard binary retrieval methods.

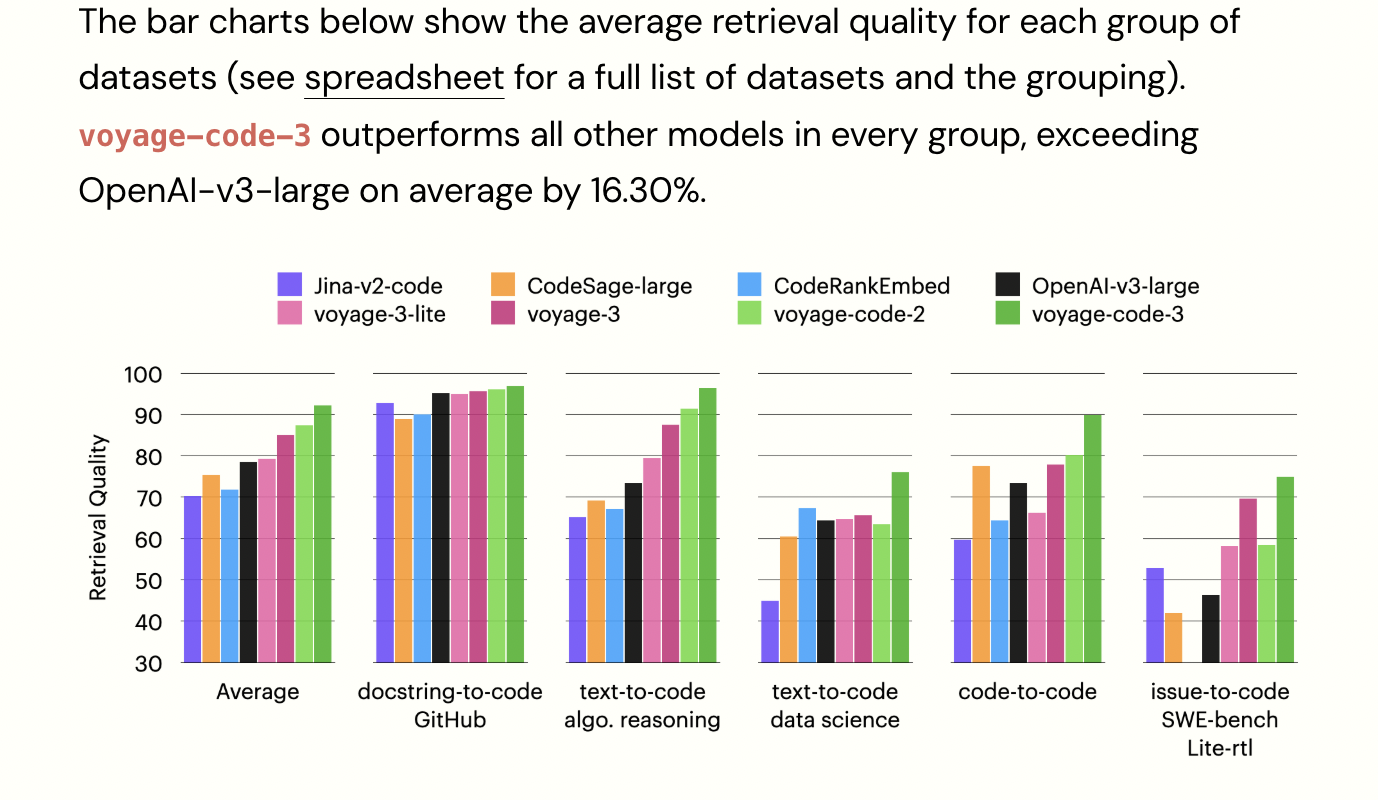
Voyage-code-3 emerges as an innovative embedding model that sets new benchmarks in code retrieval technology. The model demonstrates exceptional performance, significantly surpassing existing solutions like OpenAI-v3-large and CodeSage-large across a comprehensive suite of 238 code retrieval datasets. With impressive average performance improvements of 13.80% and 16.81%, respectively, voyage-code-3 represents a significant leap forward in embedding model capabilities. Its versatile design supports multiple embedding dimensions ranging from 256 to 2048, providing users with unprecedented flexibility in balancing retrieval quality and computational efficiency.
Check out the Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link











{kind=link}