

















































The field of robotic manipulation has witnessed a remarkable transformation with the emergence of vision-language-action (VLA) models. These advanced computational frameworks have demonstrated significant potential in executing complex manipulation tasks across diverse environments. Despite their impressive capabilities, VLA models encounter substantial challenges in generalizing across novel contexts, including different objects, environments, and semantic scenarios.
The fundamental limitation stems from current training methodologies, particularly supervised fine-tuning (SFT), which predominantly relies on behavioral imitation through successful action rollouts. This approach restricts models from developing a comprehensive understanding of task objectives and potential failure mechanisms. Consequently, the models often struggle to adapt to nuanced variations and unforeseen scenarios, highlighting the critical need for more sophisticated training strategies.
Previous research in robotic learning predominantly employed hierarchical planning strategies, with models like Code as Policies and EmbodiedGPT utilizing large language models and vision-language models to generate high-level action plans. These approaches typically utilize large language models to create action sequences, followed by low-level controllers to resolve local trajectory challenges. However, such methodologies demonstrate significant limitations in skill adaptability and generalization across everyday robotic manipulation tasks.
VLA models have pursued two primary approaches to action planning: action space discretization and diffusion models. The discretization approach, exemplified by OpenVLA, involves uniformly truncating action spaces into discrete tokens, while preserving autoregressive language decoding objectives. Diffusion models, conversely, generate action sequences through multiple denoising steps rather than producing singular stepwise actions. Despite these structural variations, these models consistently rely on supervised training using successful action rollouts, which fundamentally constrains their generalizability to novel manipulation scenarios.
Researchers from UNC Chapel-Hill, the University of Washington, and the University of Chicago introduce GRAPE (Generalizing Robot Policy via Preference Alignment), an innovative approach designed to address fundamental limitations in VLA model training. GRAPE presents a robust trajectory-wise preference optimization (TPO) technique that strategically aligns robotic policies by implicitly modeling rewards from successful and unsuccessful trial sequences. This methodology enables enhanced generalizability across diverse manipulation tasks by moving beyond traditional training constraints.
At the core of GRAPE’s approach is a sophisticated decomposition strategy that breaks complex manipulation tasks into multiple independent stages. The method offers unprecedented flexibility by utilizing a large vision model to propose critical keypoints for each stage and associating them with spatial-temporal constraints. These customizable constraints allow alignment with varied manipulation objectives, including task completion, robot interaction safety, and operational cost-efficiency, marking a significant advancement in robotic policy development.
The research team conducted comprehensive evaluations of GRAPE across simulation and real-world robotic environments to validate its performance and generalizability. In simulation environments like Simpler-Env and LIBERO, GRAPE demonstrated remarkable capabilities, outperforming existing models Octo-SFT and OpenVLA-SFT by significant margins. Specifically, in Simpler-Env, GRAPE exceeded the performance of previous models by an average of 24.48% and 13.57%, respectively, across various generalization aspects including subject, physical, and semantic domains.
The real-world experimental results further substantiated GRAPE’s effectiveness, with the model showcasing exceptional adaptability across diverse task scenarios. In in-domain tasks, GRAPE achieved a 67.5% success rate, representing a substantial 22.5% improvement over OpenVLA-SFT and dramatically surpassing Octo-SFT. Particularly impressive was GRAPE’s performance in challenging generalization tasks, where it maintained superior results across visual, action, and language grounding scenarios, with an impressive total average success rate of 52.3% – a significant 19% advancement over existing approaches.
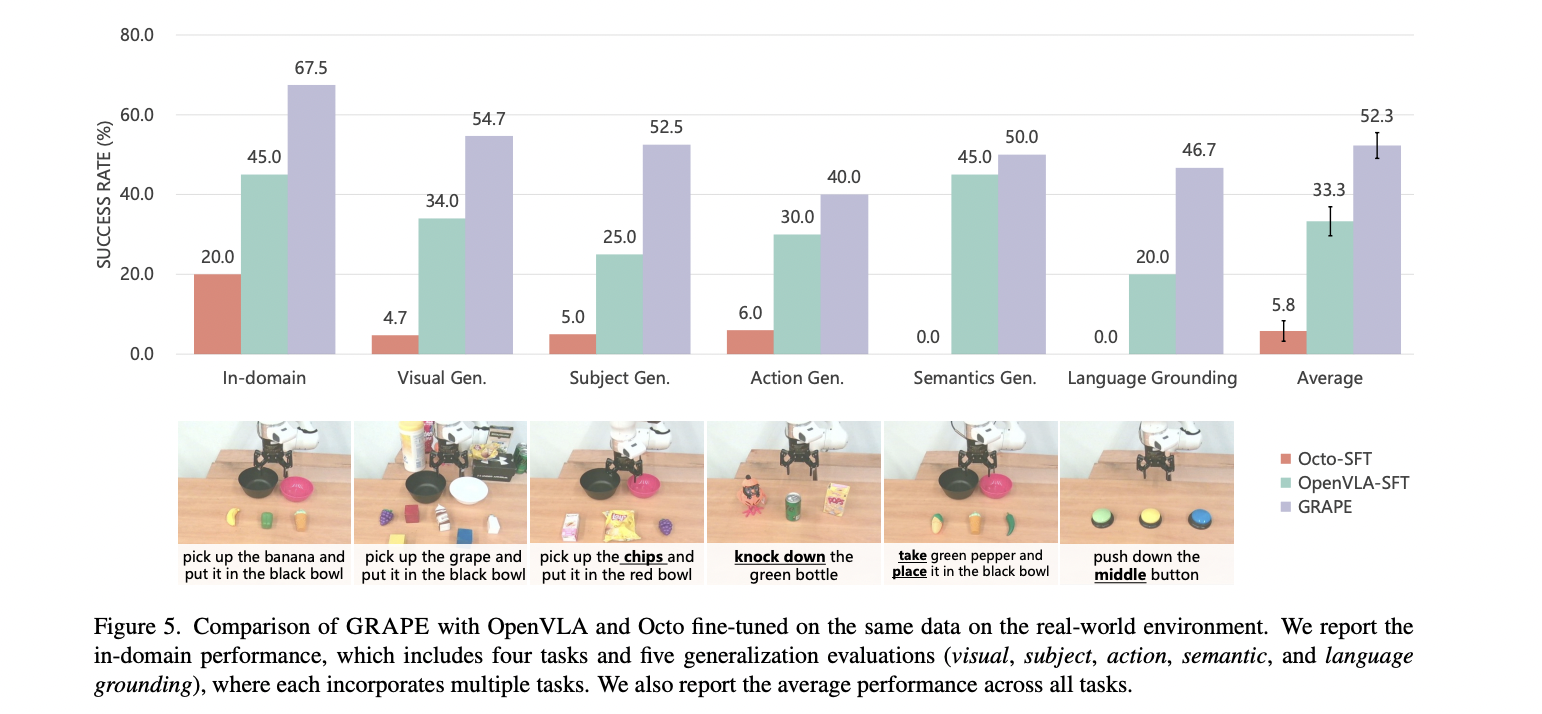
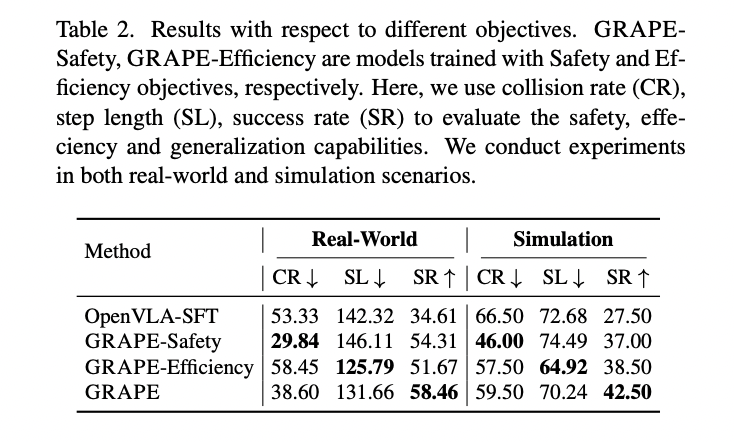
This research introduces GRAPE as a transformative solution to critical challenges confronting VLA models, particularly their limited generalizability and adaptability across manipulation tasks. By implementing a novel trajectory-level policy alignment approach, GRAPE demonstrates remarkable capability in learning from both successful and unsuccessful trial sequences. The methodology offers unprecedented flexibility in aligning robotic policies with diverse objectives, including safety, efficiency, and task completion through innovative spatiotemporal constraint mechanisms. Experimental findings validate GRAPE’s significant advancements, showcasing substantial performance improvements across in-domain and unseen task environments.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link










{kind=link}