
















































Diffusion models have set new benchmarks for generating realistic, intricate images and videos. However, scaling these models to handle high-resolution outputs remains a formidable challenge. The primary issues revolve around the significant computational power and complex optimization processes required, which make it difficult to implement these models efficiently in practical applications.
One of the central problems in high-resolution image and video generation is the inefficiency and resource intensity of current diffusion models. These models must repeatedly reprocess entire high-resolution inputs, which is time-consuming and computationally demanding. Moreover, the need for deep architectures with attention blocks to manage high-resolution data further complicates the optimization process, making achieving the desired output quality even more challenging.
Traditional methods for generating high-resolution images typically involve a multi-stage process. Cascaded models, for example, create pictures at lower resolutions first and then enhance them through additional stages, resulting in a high-resolution output. Another common approach is using latent diffusion models, which operate in a downsampled latent space and depend on auto-encoders to generate high-resolution images. However, these methods come with challenges, such as increased complexity and a potential drop in quality due to the inherent compression in the latent space.
Researchers from Apple have introduced a groundbreaking approach known as Matryoshka Diffusion Models (MDM) to address these challenges in high-resolution image and video generation. MDM stands out by integrating a hierarchical structure into the diffusion process, eliminating the need for separate stages that complicate training and inference in traditional models. This innovative method enables the generation of high-resolution content more efficiently and with greater scalability, marking a significant advancement in the field of AI-driven visual content creation.
The MDM methodology is built on a NestedUNet architecture, where the features and parameters for smaller-scale inputs are embedded within those of larger scales. This nesting allows the model to handle multiple resolutions simultaneously, significantly improving training speed and resource efficiency. The researchers also introduced a progressive training schedule that starts with low-resolution inputs and gradually increases the resolution as training progresses. This approach speeds up the training process and enhances the model’s ability to optimize for high-resolution outputs. The architecture’s hierarchical nature ensures that computational resources are allocated efficiently across different resolution levels, leading to more effective training and inference.
The performance of MDM is noteworthy, particularly in its ability to achieve high-quality results with less computational overhead compared to existing models. The research team from Apple demonstrated that MDM could train high-resolution models up to 1024×1024 pixels using the CC12M dataset, which contains 12 million images. Despite the relatively small size of the dataset, MDM achieved strong zero-shot generalization, meaning it performed well on new data without the need for extensive fine-tuning. The model’s efficiency is further highlighted by its ability to produce high-resolution images with Frechet Inception Distance (FID) scores that are competitive with state-of-the-art methods. For instance, MDM achieved a FID score of 6.62 on ImageNet 256×256 and 13.43 on MS-COCO 256×256, demonstrating its capability to generate high-quality images efficiently.
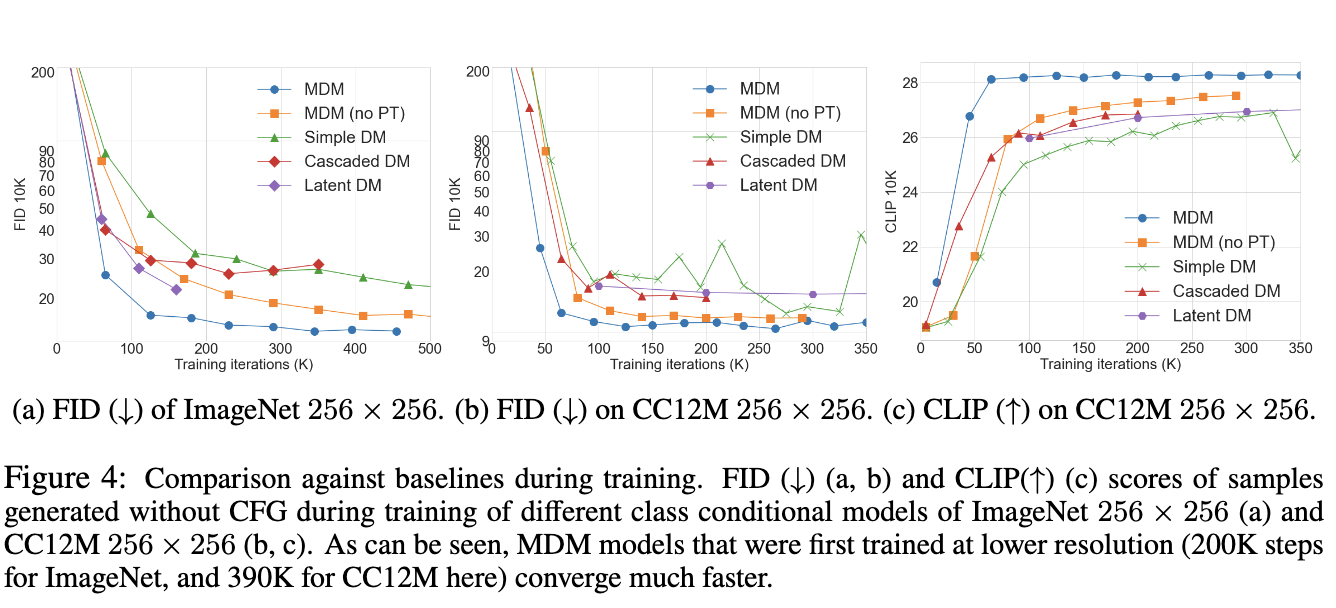
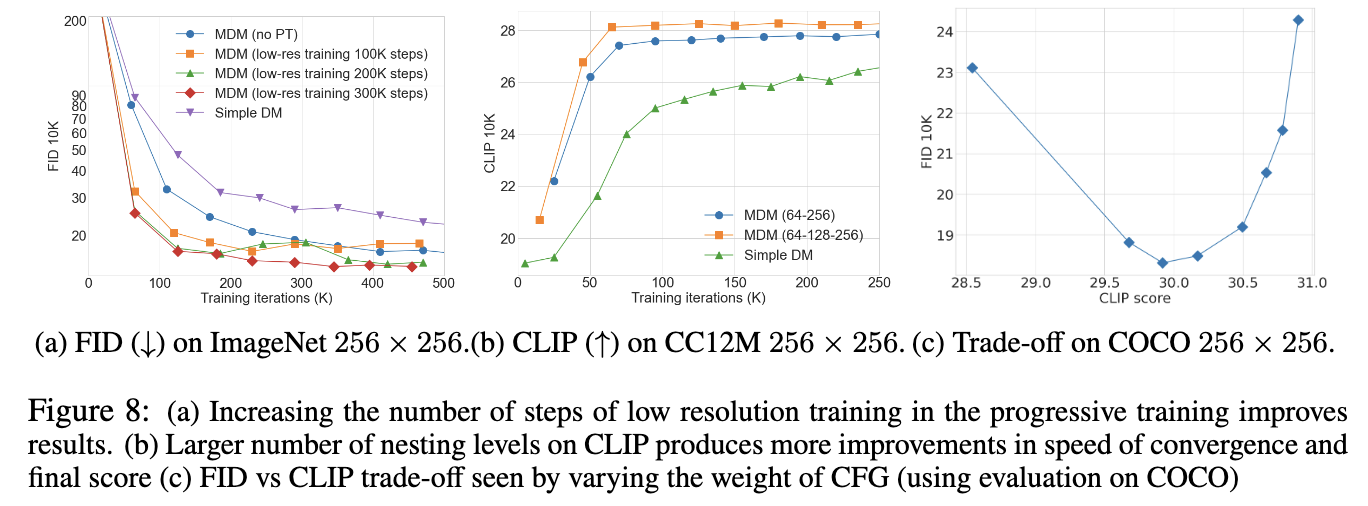
In conclusion, the introduction of Matryoshka Diffusion Models by researchers at Apple represents a significant step forward in high-resolution image and video generation. By leveraging a hierarchical structure and a progressive training schedule, MDM offers a more efficient and scalable solution than traditional methods. This advancement addresses the inefficiencies and complexities of existing diffusion models and paves the way for more practical and resource-efficient applications of AI-driven visual content creation. As a result, MDM holds great potential for future developments in the field, providing a robust framework for generating high-quality images and videos with reduced computational demands.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link











{kind=link}