
















































Feedback is crucial for student success, especially in large computing classes facing increasing demand. Automated tools, incorporating analysis techniques and testing frameworks, are gaining popularity but often need more helpful suggestions. Recent advancements in large language models (LLMs) show promise in offering rapid, human-like feedback. However, concerns about the accuracy, reliability, and ethical implications of using proprietary LLMs persist, necessitating exploring open-source alternatives in computing education.
Automated feedback generation in computing education has been a persistent challenge, focusing mainly on identifying mistakes rather than offering constructive guidance. LLMs present a promising solution to this issue. Recent research has explored using LLMs for automated feedback generation but highlights limitations in their performance. While some studies show LLMs like GPT-3 and GPT-3.5 can identify issues in student code, they also exhibit inconsistencies and inaccuracies in feedback. Also, current state-of-the-art models struggle to match human performance when providing programming exercise feedback. The concept of using LLMs as judges to evaluate other LLMs’ output, termed LLMs-as-judges, has gained traction. This approach has shown promising results, with models like GPT-4 reaching high levels of agreement with human judgments.
Researchers from Aalto University, the University of Jyväskylä, and The University of Auckland provide a thorough study to assess the effectiveness of LLMs in providing feedback on student-written programs and to explore whether open-source LLMs can rival proprietary ones in this regard. The focus lies on feedback that detects errors in student code, such as compiler errors or test failures. Initially, evaluations compare programming feedback from GPT-4 with expert human ratings, establishing a baseline for assessing LLM-generated feedback quality. Subsequently, the study evaluates feedback quality from various open-source LLMs compared to proprietary models. To address these research questions, existing datasets and new feedback generated by open-source models are assessed using GPT-4 as a judge.
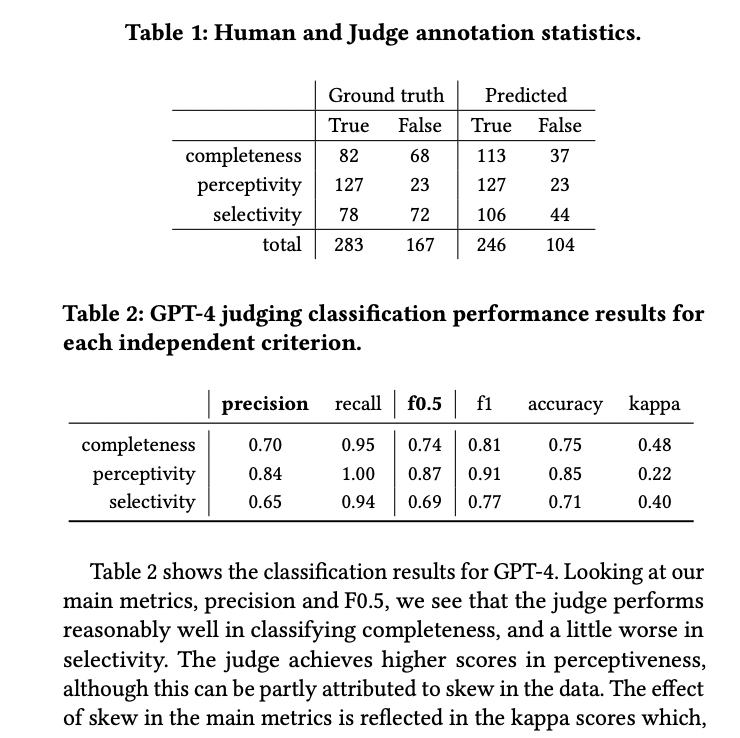
Data from an introductory programming course by Aalto University was utilized, consisting of student help requests and feedback generated by GPT-3.5. Evaluation criteria focused on feedback completeness, perceptivity, and selectivity. Feedback was assessed both qualitatively and automatically using GPT-4. Open-source LLMs were evaluated alongside proprietary ones, employing a rubric-based grading system. GPT-4 judged the quality of feedback generated by LLMs based on human annotations. Precision and F0.5-score were key metrics used to evaluate the judge’s performance.
The results show that while most feedback is perceptive, only a little over half is complete, and many contain misleading content. GPT-4 tends to grade feedback more positively compared to human annotators, indicating some positive bias. Classification performance results for GPT-4 show reasonably good performance in completeness classification and slightly lower performance in selectivity. Perceptivity classification scores higher, partially due to data skew. Kappa scores indicate moderate agreement, with GPT-4 maintaining high recall across all criteria while maintaining reasonable precision and accuracy.
To recapitulate, this study examined the effectiveness of GPT-4 in evaluating automatically generated programming feedback and assessed the performance of various large language models, including open-source ones, in generating feedback on student code. Results indicate that GPT-4 shows promise in reliably assessing the quality of automatically generated feedback. Also, open-source language models demonstrate the potential to generate programming feedback. This suggests that LLM-generated feedback could serve as a cost-effective and accessible resource in learning environments, allowing instructors and teaching assistants to focus on more challenging cases where LLMs may currently fall short in assisting students.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
![]()
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.
Credit: Source link










{kind=link}