
















































Recent advancements in conversational question-answering (QA) models have marked a significant milestone. The introduction of large language models (LLMs) such as GPT-4 has revolutionized how we approach conversational interactions and zero-shot response generation. These models have reshaped the landscape, enabling more user-friendly and intuitive interactions and pushing the boundaries of accuracy in automated responses without needing dataset-specific fine-tuning.
This research tackles the primary challenge of enhancing zero-shot conversational QA accuracy in LLMs. Previously experimented methods, while somewhat effective, have not fully harnessed the potential of these powerful models. The research aims to refine these methods, achieving greater accuracy and setting new benchmarks in conversational QA.
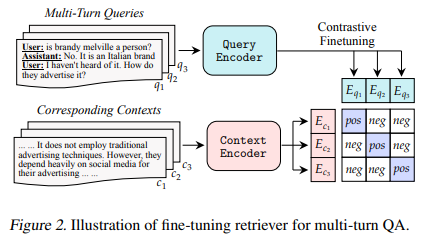
The current strategies in conversational QA primarily involve fine-tuning single-turn query retrievers on multi-turn QA datasets. While effective to a certain extent, these methods have room for improvement, especially in real-world applications. The research presents an innovative approach that promises to address these limitations further and propel conversational QA models’ capabilities.
Researchers from NVIDIA have introduced ChatQA, a pioneering family of conversational QA models designed to reach and surpass the accuracy levels of GPT-4. ChatQA employs a novel two-stage instruction tuning method that significantly enhances zero-shot conversational QA results from LLMs. This method represents a major breakthrough, substantially improving existing conversational models.
The methodology behind ChatQA is intricate and innovative. The first stage involves supervised fine-tuning (SFT) on a diverse range of datasets, which lays the foundation for the model’s instruction-following capabilities. The second stage, context-enhanced instruction tuning, integrates contextualized QA datasets into the instruction tuning blend. This two-pronged approach ensures that the model follows instructions effectively and excels in contextualized or retrieval-augmented generation in conversational QA.
One of the variants, ChatQA-70B, outperforms GPT-4 in average scores across ten conversational QA datasets, a feat achieved without relying on synthetic data from existing ChatGPT models. This outstanding performance is a testament to the efficacy of the two-stage instruction tuning method employed by ChatQA.
In conclusion, ChatQA represents a significant leap forward in conversational question answering. This research addresses the critical need for improved accuracy in zero-shot QA tasks and highlights the potential of advanced instruction tuning methods to enhance the capabilities of large language models. The development of ChatQA could have far-reaching implications for the future of conversational AI, paving the way for more accurate, reliable, and user-friendly conversational models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Efficient Deep Learning, with a focus on Sparse Training. Pursuing an M.Sc. in Electrical Engineering, specializing in Software Engineering, he blends advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” showcasing his commitment to enhancing AI’s capabilities. Athar’s work stands at the intersection “Sparse Training in DNN’s” and “Deep Reinforcemnt Learning”.

Credit: Source link










{kind=link}